Egocentric Action Anticipation con Architetture Mamba
Il problema della egocentric action anticipation consiste nel predire la prossima azione da un video acquisito mediante dispositivi indossabili.
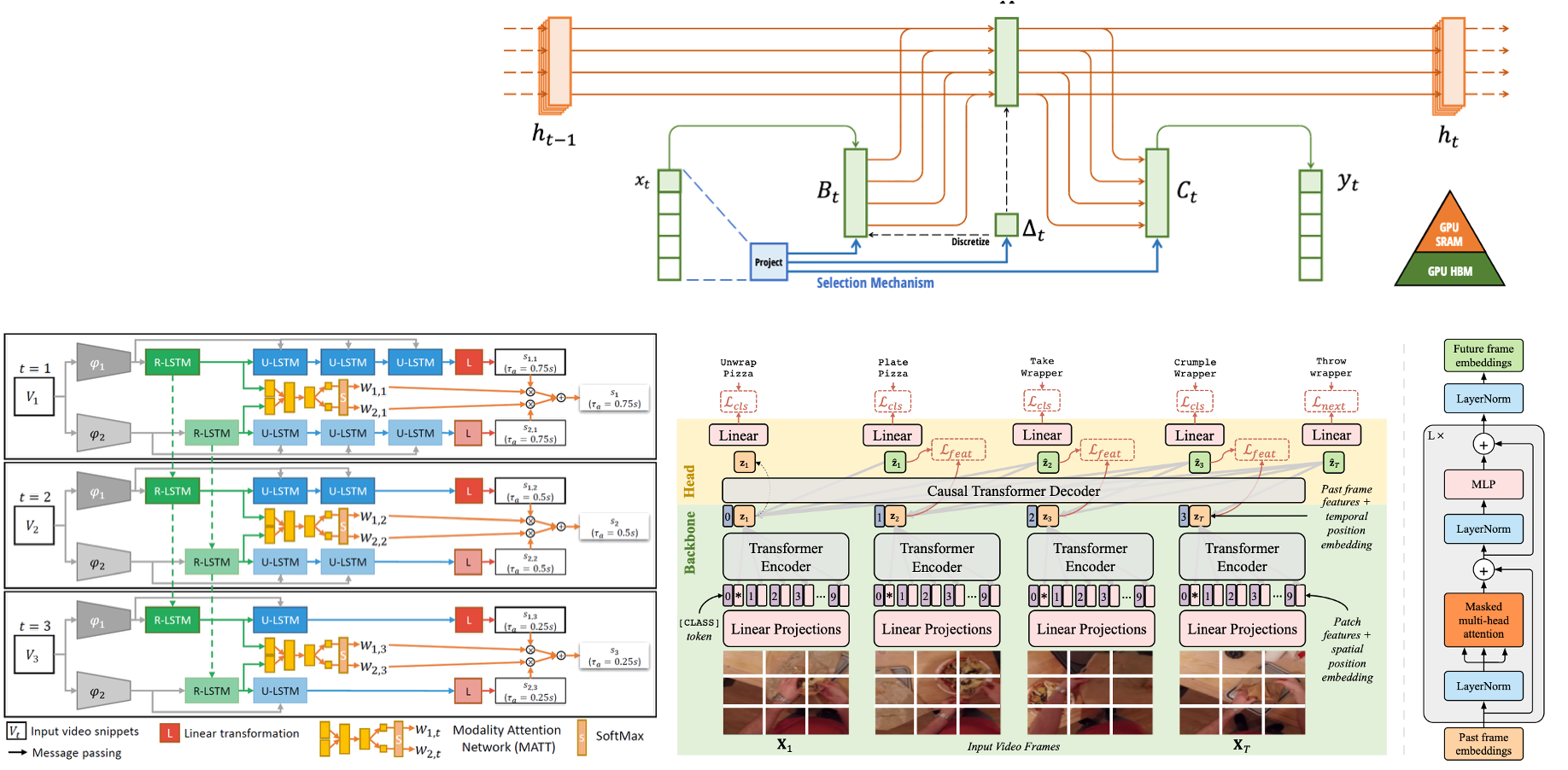
Gli approcci più recenti dello stato dell’arte di egocentric action anticipation hanno affrontato questo problema mediante l’uso di reti ricorrenti dapprima e Transformer successivamente. Questi modelli hanno però capacità limitate di gestire sequenze molto lunghe. Gli state space models, recententemente proposti, e i modelli di tipo Mamba, hanno dimostrato di essere in grado di gestire lunghe sequenze in maniera efficiente in fase di runtime.
L’obiettivo della tesi è quello di sviluppare modelli di egocentric action anticipation facendo uso di modelli di tipo Mamba e opzionalmente di Transformer.
Letture di riferimento:
- Antonino Furnari, Giovanni Maria Farinella (2021). Rolling-Unrolling LSTMs for Action Anticipation from First-Person Video. IEEE Transactions on Pattern Analysis and Machine Intelligence (PAMI), 43(11), pp. 4021-4036.
- Gu, A., & Dao, T. (2023). Mamba: Linear-time sequence modeling with selective state spaces. arXiv preprint arXiv:2312.00752.
- Vaswani, A. et al (2017). Attention is all you need. Advances in Neural Information Processing Systems.
- Chen, G., Huang, Y., Xu, J., Pei, B., Chen, Z., Li, Z., … & Wang, L. (2024). Video mamba suite: State space model as a versatile alternative for video understanding. arXiv preprint arXiv:2403.09626.