24. Clustering#
When we deal with complex datasets of multiple observations and variables, it can be useful to be able to understand the underlying structure of the data.
One approach to do so is to determine whether the data can be grouped into clusters containing points with similar characteristics. This can be useful in different application scenarios in data analysis:
Customer Segmentation:
Grouping customers based on their purchasing behavior, preferences, or demographics for targeted marketing strategies.
Image Segmentation:
Dividing an image into meaningful segments or regions based on similarity, aiding in object recognition and computer vision tasks.
Text Document Clustering:
Grouping similar documents together based on their content for tasks such as topic modeling, document organization, and information retrieval.
Speech and Audio Processing:
Clustering audio data for tasks such as speaker identification, music genre classification, and speech analysis.
E-commerce:
Grouping products or users based on purchasing patterns to optimize inventory management and improve the user experience.
24.1. Problem Definition#
Clustering aims to break the data into distinct group with similar properties. Let us consider the “Old Faithful” dataset, which comprises \(272\) observations of the eruption of the Old Faithful geyser at the Yellowstone National Park in USA. Each observation includes two variables:
The duration of the eruption in minutes;
The time in minutes to the next eruption.
We can see each observation as 2D vector which can be plotted in a Cartesian coordinate system:
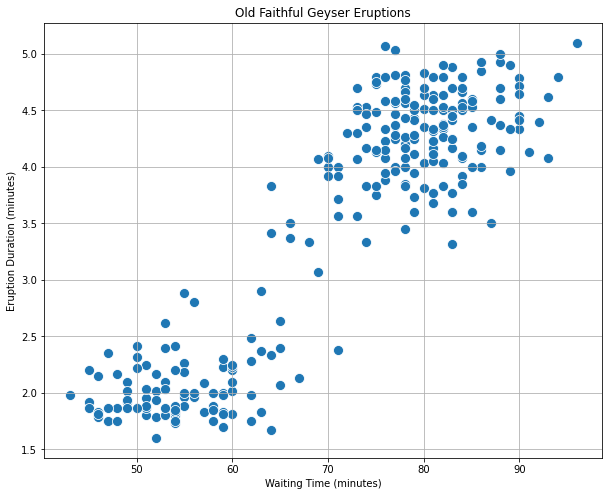
We can see how we clearly have two kinds of eruptions:
Short eruptions followed by other eruptions in a short time (bottom left);
Long eruptions followed by other eruptions in a long time (upper right).
A clustering algorithm aims to automatically find the two groups and assign each data point to the most likely group. Note that the two groups will be referred generically as “cluster \(i\)”, meaning that the algorithm will not assign any semantic meaning to the clusters, but it will aim to put “similar” data points in the same cluster.
Let
be a set of observations. The goal of clustering is to split \(\mathbf{X}\) into \(K\) groups (called clusters):
Such that:
The clusters are expected to be such that elements within a group are similar to each other, whereas elements belonging to different groups are different from each other.
The number of clusters \(\mathbf{K}\) is often a hyper-parameter of the algorithm.
24.1.1. Graphical Example#
For instance, consider the following 2D points:
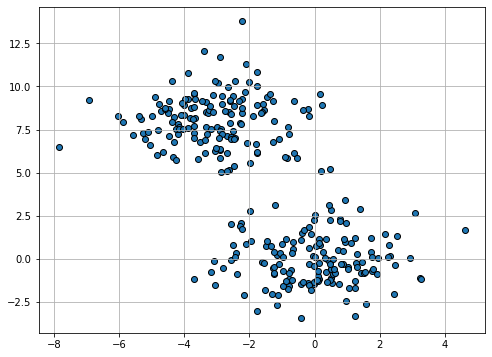
Even if we the points are not explicitly assigned to given groups (i.e., we are not observing any discrete variable \(y\) indicating the group to which each point belong), we can clearly see that there are two distinct groups (the one in the top-left part of the plot, and the one in bottom-right). The goal of clustering is to split the data into two groups, as it is shown below:
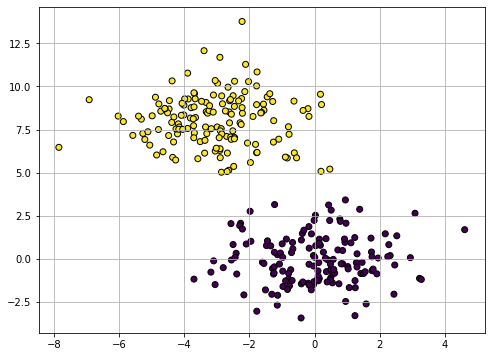
Also note that, while different possible partitions of the 2D points are possible, the one outlined in the plot guarantees that points within the same group are similar to one another (i.e., their Euclidean distance is small), whereas points from different groups have are dissimilar (i.e., their Euclidean distance is large).
24.2. K-Means Clustering#
K-Means is the most popular clustering algorithm. As in the definition we just gave of clustering, the goal of K-Means is to break the data
into \(K\) clusters
such that:
More specifically, K-Means attempts to create \(K\) clusters which are as compact as possible, where \(K\) is a parameter specified by the user (its application may depend on the application).
We will start by defining \(K\) different vectors \(\mathbf{\mu}_k \in \Re^n\) which will act as prototypes for our clusters. We will shortly see that these vectors will be the cluster’s centers.
Hence, we define \(N \times K\) binary variables \(r_{ij}\) which will allow us to establish a mapping between data points \(\mathbf{x}^{(i)}\) and clusters \(S_j\). In particular, we will define:
The notion that clusters should be as compact as possible is formalized by defining the following cost function, which is sometimes called also distortion function:
Note that this function accumulates the sum of square distances between each data point and the prototype of the assigned cluster. This is possible because \(r_{ij}\) will be one only in the if data point \(i\) is in cluster \(j\) (so many terms in the internal sum will be zero).
We can also note that the variance of cluster \(j\) can be defined as:
We can hence see the cost function also as:
Hence, minimizing \(J\) will effectively minimize the variances \(\sigma_j^2\) and the number of elements in each cluster \(|S_j|\), which will hence be encouraged to have similar numbers of elements.
The K-Means problem is solved by finding a partition \(\widehat{S}\) minimizing the cost function:
24.2.1. Optimization#
The minimization above can be performed using an iterative algorithm. The first step of the algorithm is to choose \(K\) random centroids \(\mathbf{\mu}_{i}\). After this initialization, the algorithm iterates the following two steps:
Assignment
Eeach element \(\mathbf{x}\) is assigned to the set with the closest centroid
\[\begin{split}r_{ij} = \begin{cases}1 & \text{ if } j=\arg_k\min ||\mathbf{x}^{(i)}-\mathbf{\mu}_j||^2 \\ 0 & \text{otherwise} \end{cases}, \forall i,j\end{split}\]Which will lead to the partition:
\[S_{i} = \left\{ \mathbf{x} \in \mathbf{X} :\ \left\| \mathbf{x} - \mathbf{\mu}_{i} \right\|^{2} \leq \left\| \mathbf{x} - \mathbf{\mu}_{j} \right\|^{2}\ \ \forall\ j \in \left\{ 1,\ldots K \right\} \right\}\]
Update
The centroids \(\mathbf{\mu}_{i}\) are re-computed from the assigned sets
\[\mathbf{\mu}_{j} = \frac{1}{|S_{j}|}\sum_{\mathbf{x} \in S_{j}}^{}\mathbf{x} = \frac{\sum_{i = 1}^{N}{r_{ij}\mathbf{x}^{(i)}}}{\sum_{i = 1}^{N}{r_{ij}}}\]
The algorithm converges when the update does not change any centroid. In some cases, the algorithms may never actually converge, hence it is often common to introduce as a termination criterion a maximum number of iterations.
The algorithm is not guaranteed to find the global optimum and the solution reached may depend on the random initialization. However, in practice it usually leads to a reasonable solution.
24.2.1.1. Pseudocode#
We can see the optimization algorithm in pseudo-code as follows:
Randomly initialize \(K\) cluster centroids \(\mu_{1},\mu_{2},\ldots,\mu_{K} \in \mathfrak{R}^{n}\)
Repeat until termination criterion is reached {
for i = 1 to N
\(r_{ij} = \begin{cases}1 & \text{ if } j=\arg_k\min ||\mathbf{x}^{(i)}-\mathbf{\mu}_j||^2 \\ 0 & \text{otherwise} \end{cases}, \forall i,j\) //assignment
for j = 1 to K
\(\mathbf{\mu}_{j} = \frac{\sum_{i = 1}^{N}{r_{ij}\mathbf{x}^{(i)}}}{\sum_{i = 1}^{N}{r_{ij}}}\) //update
}
24.2.2. Example Execution#
Let us see a graphical example of the process.
Dataset
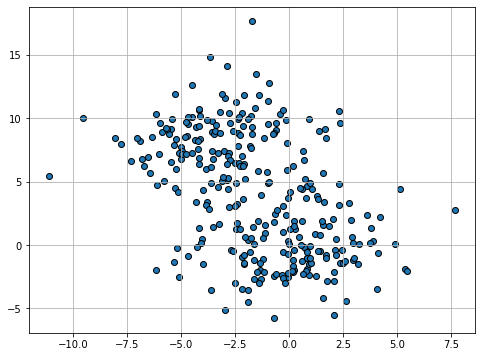
Initialization (Random)
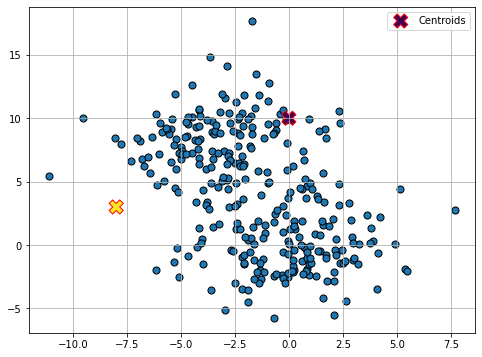
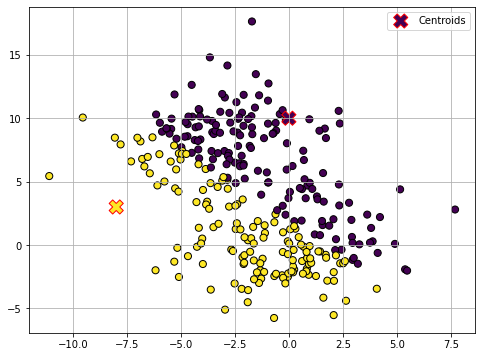
Assignment (1)
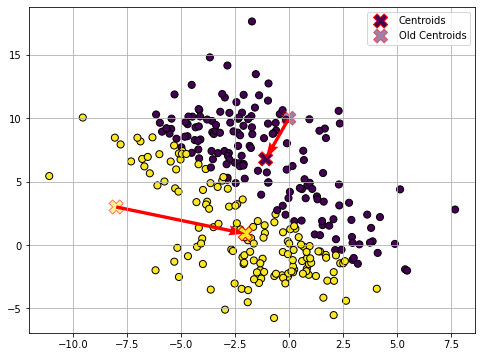
Update (1)
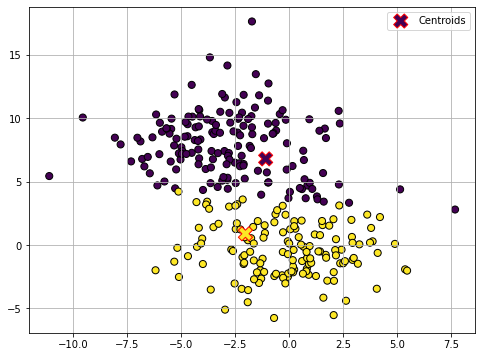
Assignment (2)
Update (2)
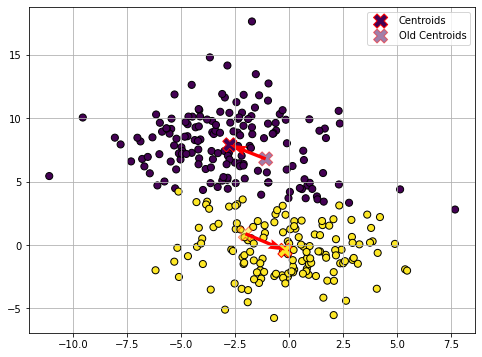
Assignment (3)
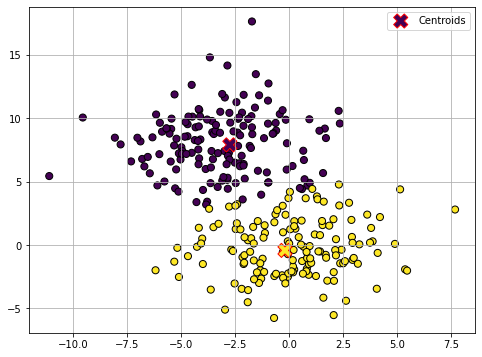
Update (3)
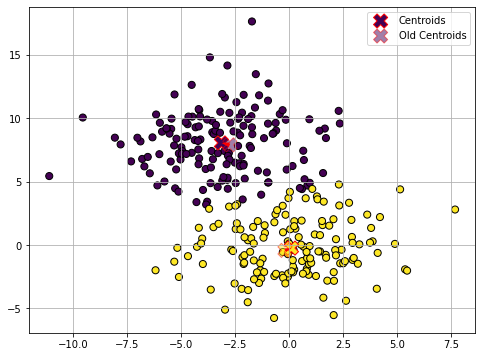
Assignment (4)
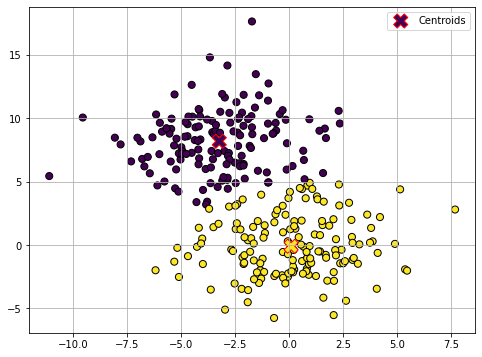
Update (4)
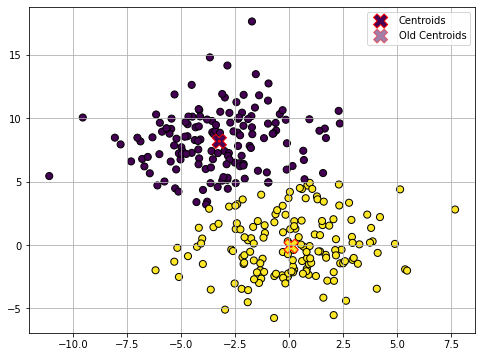
The optimization procedure terminates here as the centroids did not move in the last update step. The data is now clustered in two groups.
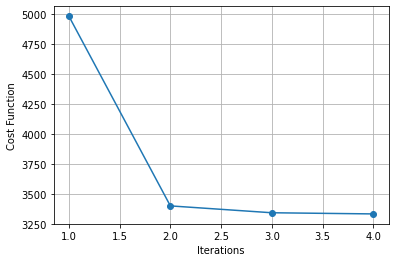
The plot below shows the value of the cost function at the end of each iteration:
24.2.3. Choosing the Right Value for K#
In the K-Means clustering algorithm, \(K\) is a hyper-parameter. This means that it is a parameter of the method affecting the final model we obtain after the optimization procedure, but its value is not automatically determined by the optimization procedure.
One common approach to determine the values of hyper-parameters is to make some guesses and fit different models with the guessed values of the hyper-parameters. We can then choose the model which has the “best value” of the considered hyper-parameters.
When it turns to determining the optimal \(K\) value for K-Means clustering, there are two main techniques which are commonly used: the elbow method and the silhouette method, which are discussed in the following.
Note that these are both heuristic methods not giving many guarantees on the final selection of \(K\), but they can still help decide on the number of clusters, in particular if guided by an intuition of what a good value of \(K\) would look like.
24.2.3.1. Elbow Method#
The elbow method consists in fitting K-Means models for different values of \(K\). For each \(K\), we then plot the final value of the cost function. We expect that as \(K\) increases, the cost will decrease. Indeed, if \(K\) is very large (even larger than it should be), we will anyway get a smaller cost due to the fact that the presence of more clusters will inevitably lower their individual variances.
However, we expect the cost function to slow the speed of decrease in the presence of the optimal (or a good) \(K\). This is called the “elbow point” as the curve should look like an elbow. We can see it in the example below:
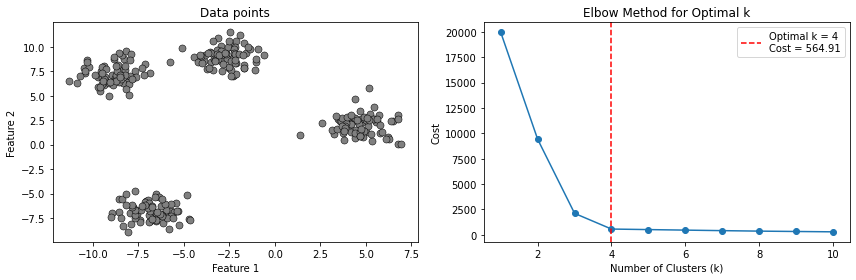
24.2.3.2. Silhouette Method#
The silhouette method tries to assess how good a given clustering model is by measuring how well the data is grouped in the identified clusters. This is done by computing, for each data point a score indicating whether how well the data point fits the assigned cluster with respect to all others.
If the model is a good one (hence a good \(K\) value), we would expect each data point to fit well its assigned cluster and not to fit well any other cluster. If this does not happen, it means that the clusters are not very well separated and we either have more or less clusters.
To do so, for a given data point \(i\) assigned to cluster \(C_I\), the silhouette method computes the following score:
where \(d(i,j)\) is the Euclidean distance between data point \(i\) and data point \(j\). In practice, the score \(a(i)\) is the average distance of data point \(i\) with any other data point assigned to the same cluster. We expect this number to be small if the cluster has a low variance.
We now want to compare this number to the value we would have if \(i\) were to be assigned to another cluster \(C_J\). In particular, we will choose the cluster \(C_J\) which minimizes the average distance. This is done by computing the following score:
Now we compare \(a(i)\) with \(b(i)\). Ideally, \(a(i)\) should be much smaller than \(b(i)\). If this happens, this means that the data point \(i\) fits in the cluster \(C_I\) much better than it would in any other cluster. To do so, we compute the silhouette score of data point \(i\) as follows:
The obtained score is such that:
In practice:
A value of \(s(i)\) close to \(1\) is obtained when \(a(i) << b(i)\), meaning that \(i\) fits in \(C_I\) much better than it would fit in any other cluster;
A value of \(s(i)\) close to \(-1\) is obtained when \(a(i) >> b(i)\), meaning that another cluster \(C_J\) exists in which \(a(i)\) fits better.
A value of \(s(i)\) close to \(0\) indicates that the data point is close to the border between two natural clusters.
The score above is arbitrarily set to \(0\) if \(|C_I|=1\) as, in that case, the cluster would only contain the data point \(i\). Note that this is an assumption of neutrality.
The correct number of clusters is usually chosen by showing the silhouette plot, which displays all the silhouette scores of data points within each clusters, arranged from largest to smallest. The plots below are taken from the scikit-learn documentation and show examples of silhouette plots for different choices of \(K\) in an example dataset:
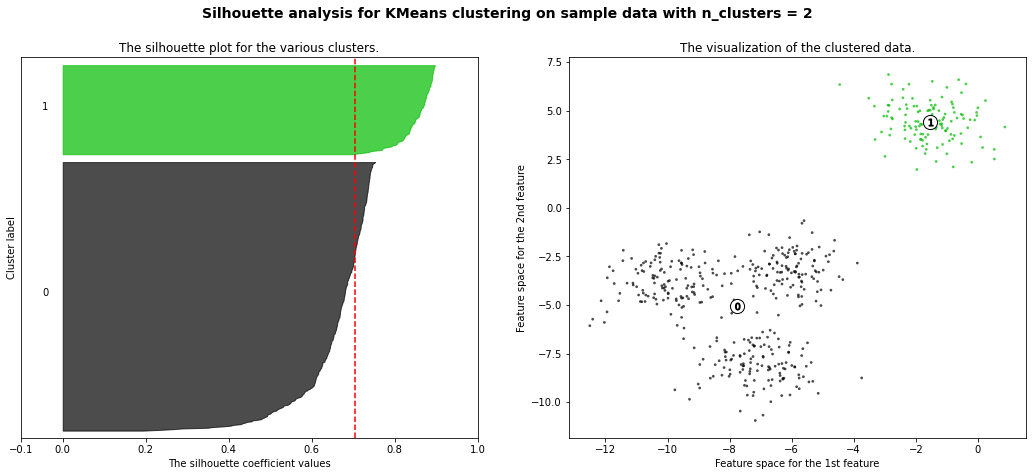
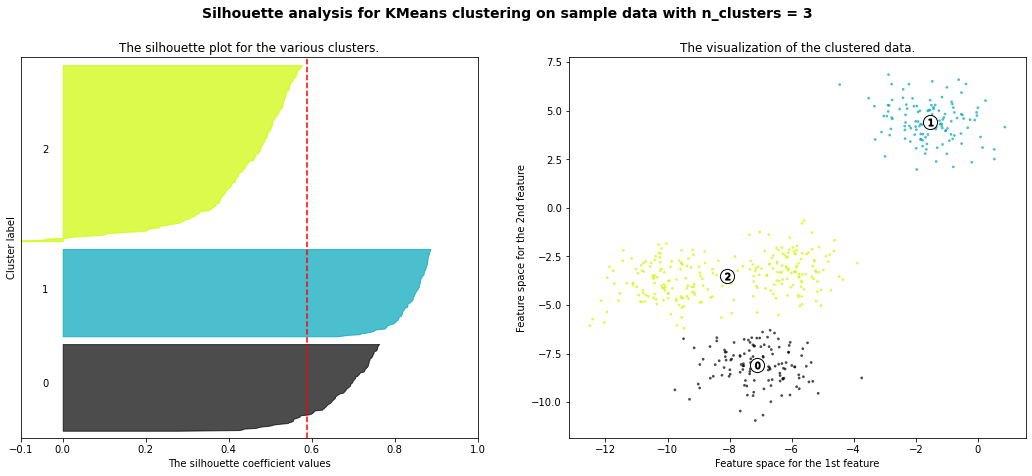
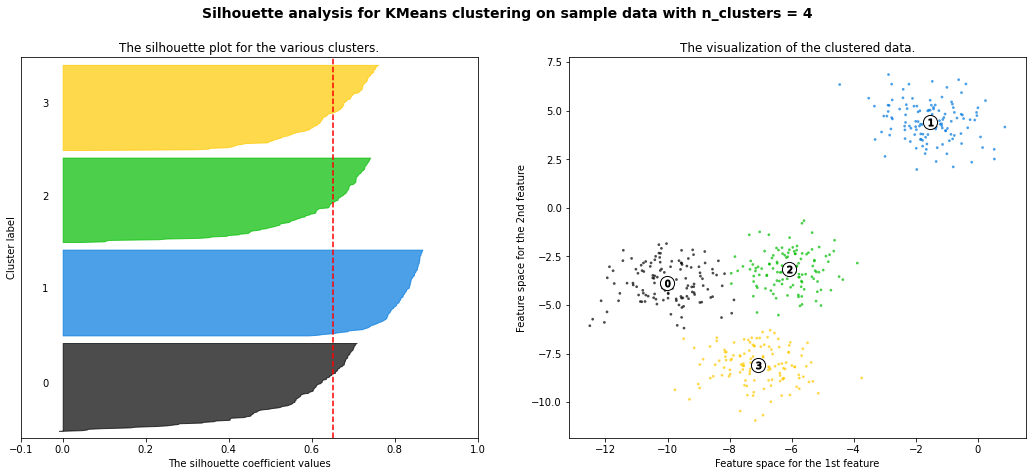
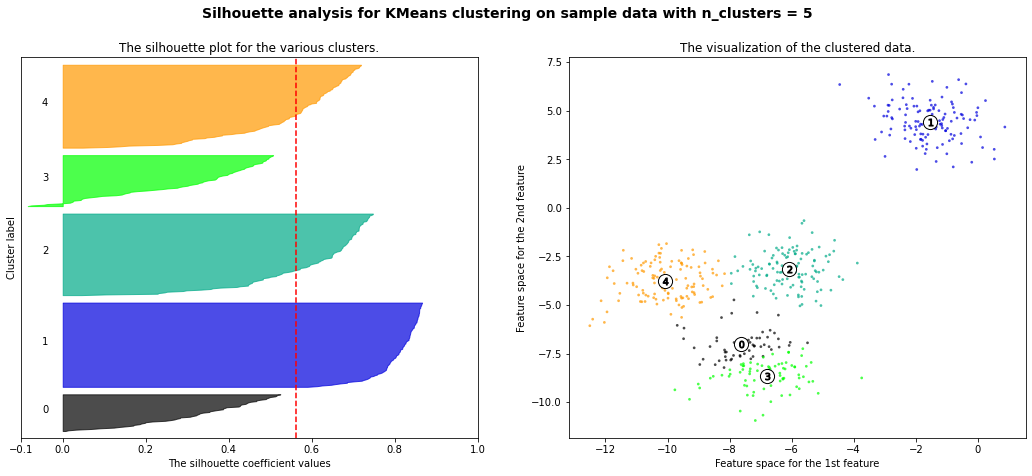
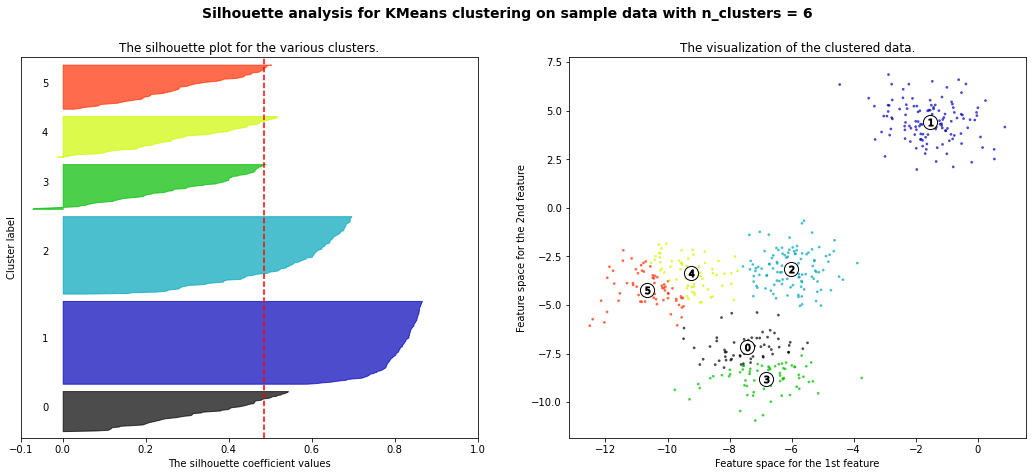
The vertical line in red displays the average silhouette score. Good choices of cluster numbers will have silhouette plots which achieve values similar to each other and close to the average one. For example \(n=2\) and \(n=4\) seem to be the best ones.
In practice, it is also useful to plot the average silhouette score versus the number of clusters and choose value of \(K\) which maximizes the average score.
Such plot would be as follows for the previous example:
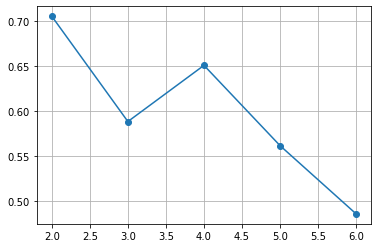
The plot below shows another example of such plot for a different dataset:
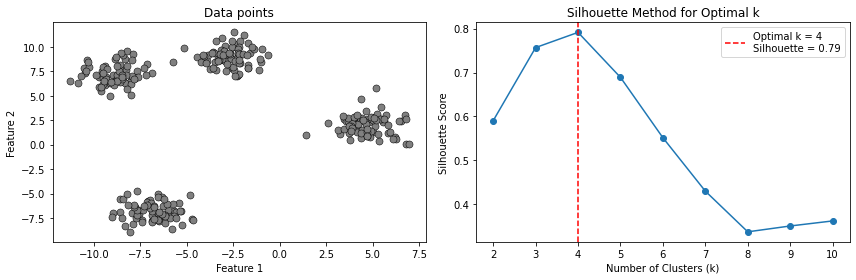
24.3. Other Clustering Algorithms#
It is important to note that various clustering algorithms exist beyond the commonly discussed k-means method. While k-means is a popular and widely used algorithm for partitioning data into distinct groups based on similarity, it is one approach among many. Numerous other clustering algorithms offer different perspectives and address specific challenges. Some examples include hierarchical clustering, DBSCAN (Density-Based Spatial Clustering of Applications with Noise), and spectral clustering. These alternatives provide unique strengths and are tailored to different types of data and scenarios. While our focus has been on understanding clustering in general and the k-means algorithm in particular, it is important to know that other approaches may be more suitable depending on the specific problem at hand. In the next lectures, we will see Gaussian Mixture Models (GMMs), a probabilistic model for density estimation which can also be interpreted as a clustering algorithm.
24.4. References#
Section 10.3.1 of [1]
Section 2.3.9 of [2]
Section 9.2 of [2]
[1] James, G., Witten, D., Hastie, T., & Tibshirani, R. (2013). An introduction to statistical learning. New York: springer.
[2] Bishop, Christopher M., and Nasser M. Nasrabadi. Pattern recognition and machine learning. Vol. 4. No. 4. New York: springer, 2006.