28. Introduction to Predictive Modelling and Regression Models#
Algorithms and techniques seen so far have been focusing on understanding the data in different ways. We have seen methods to summarize the data, study the relationship between variables, including cause-effect relationships, infer properties of the population which the observed data follow, study the internal structure of data, its density, and perform automated feature extraction with Principal Component Analysis.
We will now look at data analysis from another perspective, the one of predictive modelling. The main goal of predictive modelling is to build models which can make be used to make predictions on unseen data. Predictive modelling is a broad field of data analysis, which is very overlapped with machine learning.
It is worth mentioning that predictive modelling is a shift in thinking with respect to the approaches seen so far. For instance, we have seen how a linear regressor attempts to predict \(y\) from \(x\). This is a form of predictive modelling, but the goal so far has been to understand the relationship between \(x\) and \(y\), rather than making accurate predictions. Indeed, we have focused on interpreting the coefficients and making hypothesis tests to check if our conclusions would extend to the population as well. We have also seen how a simpler model with inferior predictive abilities can sometimes be preferred to a more complex model due to its interpretability.
The goal of predictive modelling is to create data models that can support decision making. Examples of uses of such models are:
Determining the probability of a given patient developing a given pathology from a blood test;
Determining if a given bank transaction is a fraudulent one (anomaly detection);
Predicting the future value of a company stock;
Estimating the energy produced by a solar plant based on weather forecast;
Predict whether an autonomous vehicle should turn left or right given sensor readings and an RGB image observation of the scene.
Detect the presence of people from surveillance cameras.
In these cases, we aim to obtain accurate systems, but we are less interested in their interpretability. Indeed, while being able to interpret such models is certainly a plus, we will often prefer more complex but accurate models even if we loose the ability to interpret them.
28.1. Problem Formulation#
We will give a general formulation of predictive modelling problems. Later, we will see instantiations of this formulation to specific predictive modeling problems.
Let \(\mathcal{X}\) and \(\mathcal{Y}\) be two spaces of objects. We can see them as the sample spaces of two random variables \(X\) and \(Y\), with \(x \in \mathcal{X}\) and \(y \in \mathcal{Y}\) being two realizations of the random variables: \(X=x\) and \(Y=y\). The goal of predictive modeling is to find a function:
which outputs an object \(y \in \mathcal{Y}\), given an object \(x \in \mathcal{X}\). We often use the symbol \(y\) to refer to the true value of \(Y=y\) associated to the observation \(X=x\), while \(\hat y\) will represent the prediction obtained using function \(h\):
The true value \(y\) is often called ground truth. The function \(h\) is usually a data model and often referred to as an hypothesis.
28.1.1. Example 1#
As a simple example, we can imagine \(\mathcal{X}=\Re^m\) and \(\mathcal{Y}=\{0,1\}\), with \(\mathbf{x} \in \Re^m\) being a numerical vector representing the results of different blood tests made on a given subject, while \(y \in \{0,1\}\) being a response variable indicating whether the given subject has (\(1\)) or does not have (\(0\)) a given disease.
Finding an appropriate function \(h\) will allow us to predict if a given subject has a given disease from the blood test \(\mathbf{x}\):
If we obtain \(\hat y = 1\), then we will assume that the given person has the disease. While this example is very abstract, we will later see algorithms which assign a specific form to \(h\).
28.1.2. Example 2#
We want to build a spam filter which decides whether a given email is spam or not. In this case, we can consider \(\mathcal{X}\) as the set of all possible emails and \(\mathcal{Y}=\{0,1\}\), with \(1\) indicating spam and \(0\) indicating non-spam. Let \(f\) be a function counting the number of orthographical mistakes of a given email \(x \in \mathcal{X}\):
We can determine if a given email \(x\) is spam or not by counting the number of mistakes and checking whether this number exceeds a pre-determined threshold \(\theta\). We can hence define our function \(h\) as follows:
As we will later see, this is a trivial example of a parametric classifier with one parameter.
28.2. Statistical Learning#
While there are different ways to define the function \(h\), the model is often obtained following an approach called statistical learning. According to the statistical learning approach, we will assume to have at our disposal a TRaining set (TR) of \(N\) examples:
where \(x_i \in \mathcal{X}\) is the input object and \(y_i \in \mathcal{Y}\) is the corresponding response that we aim to obtain with \(h(x_i)\). The term “training set” is borrowed from the machine learning terminology, where a model is “trained” on a given set of data to improve its performance in tackling a given task.
More specifically, we will assume that the examples are independent and identically distributed (i.i.d.), following the joint probability \(P(X,Y)\):
The i.i.d. hypothesis is reasonable and, as we will see later, very useful. Moreover, the assumption that the data follows the joint probability, allows us to reason in probabilistic terms, modeling the uncertainty in predictions. Hence, the predicted values will be realization of a random variable following the conditional distribution P(y|x):
To find the appropriate function \(h\), we will define (depending on the problem) a real-valued loss (or cost) function
which measures the loss, or cost of predicting \(\hat y\) when the true value is \(y\). If the prediction \(\hat{y}\) is very similar to the real value \(y\), then we will obtain a small cost (or loss value) for \(L(\hat y, y)\). In practice, the form of \(L\) will vary depending on the problem and model at hand.
We will define the risk \(R(h)\) of a given hypothesis function \(h\) as the expected loss value under the joint probability distribution:
Statistical learning aims to find the optimal \(h^*\) from a fixed class of functions \(\mathcal{H}\) by solving the following optimization problem:
Borrowing from the machine learning terminology, we will say that a model as a large capacity if the number of the associated functions \(\mathcal{H}\) is large.
28.2.1. Empirical Risk Minimization#
In general, the risk \(R(h)\) cannot be computed because the joint distribution \(P(X,Y)\) is unknown. However, by the law of large numbers, we can estimate it empirically using the training set TR:
The empirical risk minimization principle states that the we should choose a hypothesis \(\hat h\) from the class of hypothesis functions \(\mathcal{H}\) which minimizes the empirical risk:
We thus define a learning algorithm (i.e., an algorithm used to “learn” the model \(\hat h\) from the training set TR) which solves the above defined optimization problem.
28.2.2. Supervised vs Unsupervised Learning#
In the machine learning terminology, predictive models as just defined are also referred to as supervised learning algorithms, where the world “supervised” indicates that we are given input objects \(x\) and expected (or desired) out values \(y\). This is in contrast with unsupervised algorithms, in which we are only given the \(x\) values. Examples of such algorithms are the Principal Component Analysis and Clustering Algorithms.
28.3. Evaluating the Performance of a Predictive Model#
Once we choose a model \(\hat h\) minimizing the empirical risk computed on the training set, we need to evaluate the performance of the model. This is a fundamental step, as we want to know how well will the model do “in the wild”, beyond the training set.
28.3.1. Overfitting#
One may think that a model minimizing the empirical risk will be the best possible one. However, especially when the training set is not large enough (as compared to the complexity of the model) or not representative enough of the joint probability distribution \(P(X,Y)\), the estimation of the empirical risk may be limited. As an example, consider the following model:
The hypothesis \(\hat h\) defined above will lead to an empirical risk equal to \(0\) as long as the loss function is defined in such a way that \(L(y,y)=0\). Indeed:
However, the function above will not be defined for any value:
Since we expect the training set to be a sample from the distribution \(P(X,Y)\), we expect such values \(x'\) to exist (otherwise the training is the population, which is in general not true).
The example above is an extreme case of a phenomenon called overfitting, which happens when a given hypothesis achieves a low error on the training set, but the solution is not general enough to obtain similar performance (i.e., a similar risk) on data not belonging to the training set.
The phenomenon of overfitting is often related to the capacity of the model. A model with a large capacity can represent very complex functions \(h\) and result in overfitting, while a model is a small capacity can represent relatively simple functions \(h\), making overfitting harder, but possibly resulting in an underfitting model, i.e., a model which is too simple, and as a result cannot reach a low empirical risk.
This is best seen with the simple regression example below:
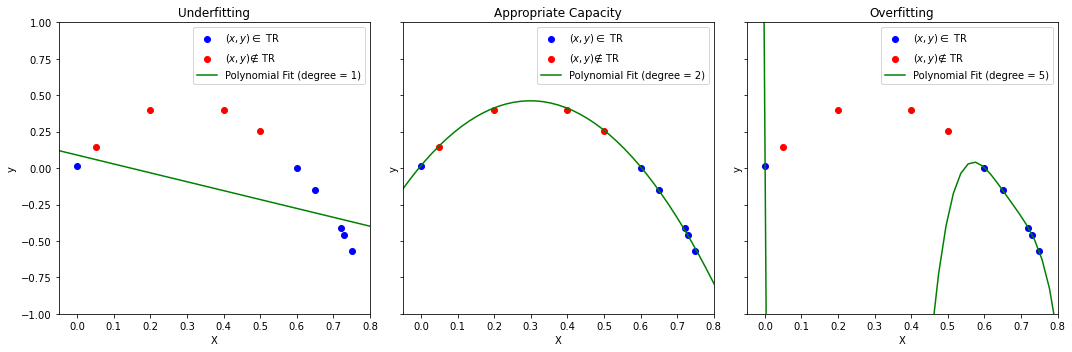
The example shows the fit of three polynomial regression models of different degrees (the first one is degree 1, which corresponds to a linear regressor). As can be noted:
A lower degree polynomial (e.g., a line - left) will lead to underfitting. In this case, the model is too simple to model the data well, so the empirical risk will be large;
A higher degree polynomial (right) will minimize the empirical risk but find a complex model which will not describe well data which has not been seen at training time. This is a case of overfitting. The model is trying to model the idiosyncrasies of the training set (which can be noisy) finding a solution which will work only on the data at hand;
An appropriate degree (center) will lead to a model with an appropriate capacity. The empirical risk is minimized and the solution also works with unseen data.
Note that this is another instance of the bias-variance tradeoff. Complex models (right) have a large variance and a large bias: small variations of the training set are modeled and can lead to wrong solutions. Models that are too simple (left) have a low variance, but can still have a large bias (the model is too simple and the solution is not good). Choosing an appropriate capacity (in this case by choosing an appropriate polynomial degree) leads to a good trade-off between variance and bias.
Regularization and Bias-Variance tradeoff In practice, there are different ways to reduce the model capacity. In the example above, the degree of the polynomial has been used as an hyperparameter to reduce the capacity of the model. A different approach would be to use regularization techniques. The plot below shows the result of fitting a polynomial regressor on the same data when Ridge regression is used:
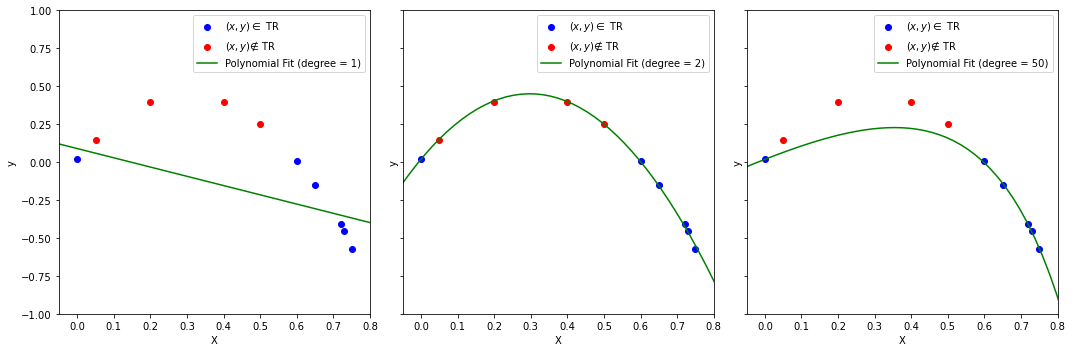
Note that even a polynomial of degree equal to \(50\) (right) achieves reasonable results now.
28.3.2. Generalization and Cross-Validation#
The example above has shown how it is possible to obtain models that work well on the training data but do not generalize to unseen data, while ideally we would want models which work well on the test data as well. We call the ability of the model to obtain a similar error (e.g., the empirical risk) on both the training set and unseen data generalization.
To measure the ability of a model to generalize, we could just take the model and use it “in the wild”. However, since we want our tests to be repeatable, we instead resort to a series of techniques which consist in using a part of our dataset as a training set and different part of the dataset as a test set. These techniques are generally referred to as cross validation. In the following, we see the main approaches to cross validation.
However, before to proceed, we should point out that, while we could evaluate the performance of a model with the empirical risk, in practice, it is common to use performance measures (the higher the better) or error measures (the lower the better) which may be different from the loss function chosen to train the algorithm. This is due to the fact that loss functions often need to have some properties to facilitate learning, so they can represent an approximation of or a deviation from our true objective measure of performance. We will see more in details the main performance measures later, but for the moment we will note that we will evaluate models using a given performance measure:
where \(Y=\{y_i | (x_i,y_i) \in S \}_{i=1}^N\) is a set of ground truth values from a set of data \(S\) and \(\hat Y = \{h(x_i) | (x_i,y_i) \in S \}_{i=1}^N\) is the set of corresponding predictions. Note that, given the definition above, the empirical risk can be seen as a performance measure, but we need not restrict to the empirical risk to evaluate predictive models.
28.3.2.1. Holdout Validation or Single Split#
The simplest form of cross-validation is the holdout test. In this case, the initial set of data is split into two different sets: a training set, which will be used to optimize the model (e.g., with empirical risk minimization) and a test set, which is used to evaluate the performance of the model. The act of optimizing the model on the training set is often called training, while the act of evaluating the performance of the model on the test set is called testing. This approach pretends that the test data is not available at training time and only uses it to evaluate performance.
The rule number one when using this technique is to avoid in any way to choose any characteristic of the model based on the training data. Indeed, if we did so, we could end up in some form of unmeasurable overfitting. To make sure that both the training and test set are i.i.d., before the split, the data is randomly shuffled.
Also, since training data is usually precious and datasets are often not large enough, it is common to split the data asymmetrically, choosing \(70-80\%\) of the data for training and \(20-30\%\) of the data for testing.
The figure below illustrates the splitting process:

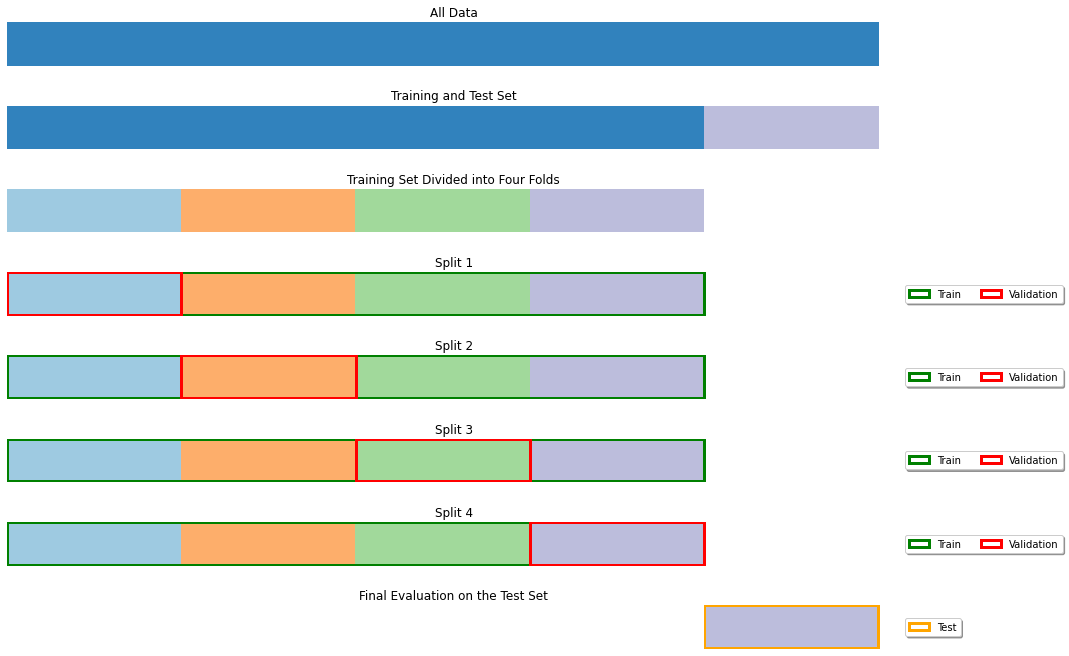
28.3.2.2. K-Fold Cross-Validation#
When the dataset is very small, we may not want to sacrifice a part of it for testing only as this may lead to a biased model. Also, we should note that a small test set could lead to a biased estimation of the model performance. In these cases, rather than randomly splitting the data into two parts, we randomly split it into \(K\) different parts, which will be called folds.
We then perform training and testing \(K\) times, each time using fold \(i\) as the test set, and the remaining folds as the training set. The final model performance is obtained by averaging the performance scores computed in each iteration. Note that the obtained performance is unbiased, as each number in the final average is computed on data which has not been seen during training.
The figure below illustrates the case of a 4-fold cross-validation.
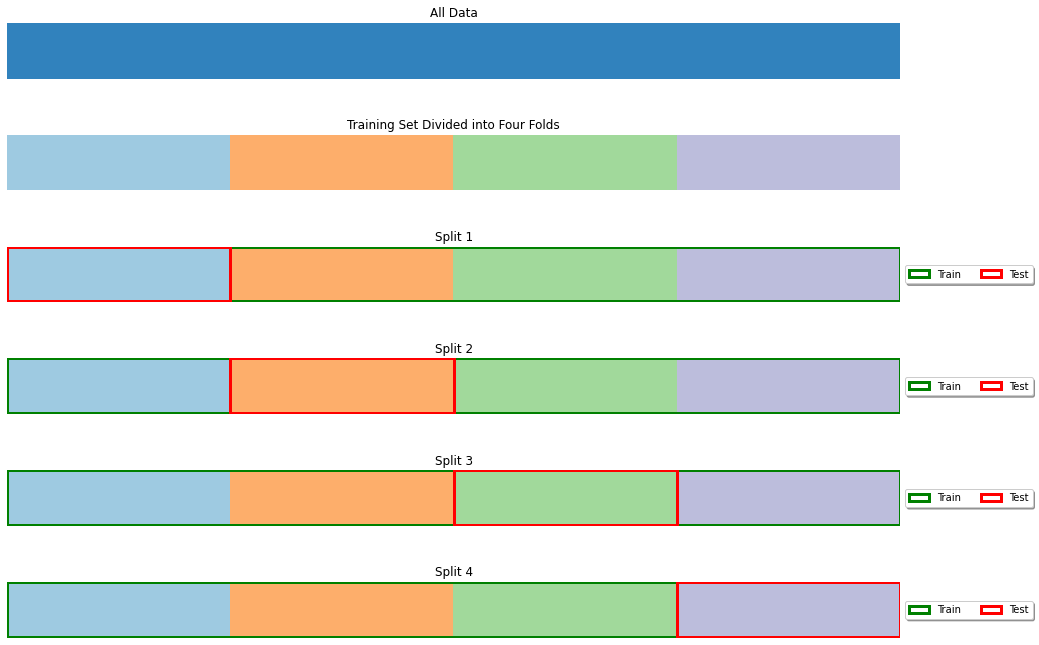
The K-Fold cross validation has the advantage of allowing to validate the model without throwing away a significant part of the data, but it is practically feasible only when the training procedure is not too computationally expensive. Indeed, if training a model takes one week, a K-Fold validation will typically require four weeks.
28.3.2.3. Leave-One-Out Cross-Validation#
In leave-one-out cross-validation, the validation stage is performed in \(N\) iterations, where \(N\) is the number of elements in the dataset. At the \(i^{th}\) iteration, the model is trained on all data points except \((x_i,y_i)\) and tested on \((x_i,y_i)\). The final performance is obtained by averaging the performance scores obtained at each iterations. Note that this is the same as K-Fold cross-validation with \(K=N\). The figure below illustrates the process:
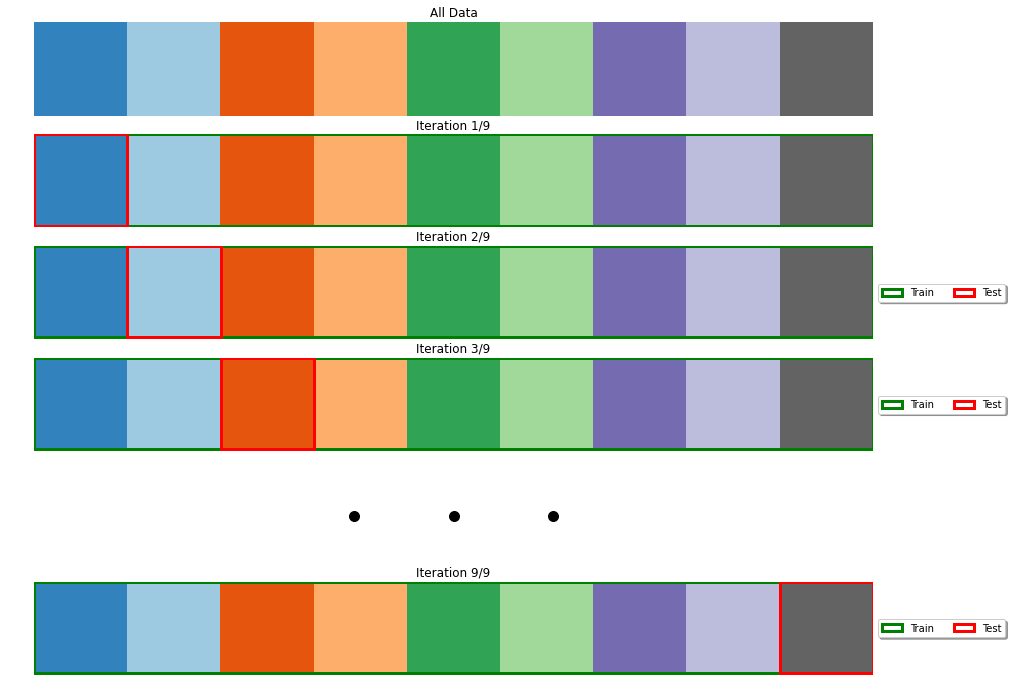
This approach is useful when the dataset is extremely small, but, similarly to K-Fold cross-validation, it can increase the computation time by a large margin.
28.4. Model Selection and Hyperparameter Optimization#
Many algorithms have some parameters which are not explicitly part of the final model \(h\), but they need to be set in order to solve the optimization problem. For example, in a ridge or lasso regressor, the parameter \(\lambda\) is used to control the amount of regularization during the learning process, however, the final parameter is not part of the model and is not automatically found during the optimization process.
Hyperparameters are usually found using grid searches: we train models using different values of the hyperparameters and choose the model which performs best. However, caution should be taken when hyperparameters are selected with grid search.
Recall that we are not allowed to make any choice on the final model using the test set. Indeed, if we did so, we may incur in a form of overfitting which we would not be able to measure. For instance, we can choose a given parameter which works well only for that specific test set. How can we be sure that performance will be good when new data is analyzed?
To avoid this problem, we should work with three different sets of data: a training set, a validation set, and a test set. We will use the training set to train the model, the validation set to choose the hyperparameters and the test set to test the final performance. This is done by training different models on the test set, choosing the hyperparameter values leading to best values on the validation set, and then re-training the model on the training set (or on the union of training and validation set) to final test on the test set.
The most common scheme is to use a fixed split with a \(60:20:20\) ratio, as shown in the following:

However, other combinations are possible. An approach which often used when the dataset is small is a follows:
The dataset is split into a training and test set;
Hyperparameters are optimized using cross-validation on the training set - this consists in executing different cross-validations with different hyperparameter values - then the parameters achieving the best performance are chosen;
Once the best hyperparameters are found, the model is re-trained on the full training set and tested on the test set.
This is illustrated in the following figure:
Again, if the dataset is large enough and the training procedure is computationally expensive, it is common to use a fixed split as illustrated above.
The scikit-learn library allows to easily perform hyperparameter search using cross-validation for different algorithms.
More in general, these techniques can be used to compare different models and select the best performing one.
28.5. Regression Predictive Models#
We will now investigate an important family of predictive models: regression models. While we have already seen regression models as approaches to understand relationships within the data, in this context we are interested in defining good hypothesis functions \(\hat h\) able to predict continuous values \(\hat y\) from continuous inputs \(x\). We can see the defined hypothesis function \(\hat h\) as an approximation of the true function \(f\) generating \(y\) from \(x\): \(y=f(x)\). We will say that we are tackling a regression problem whenever the hypothesis function takes the form:
Note that we have seen the case in which \(n=m=1\) (simple regression) and the case in which \(n>1, m=1\) (multiple regression). When both \(n>1, m>1\), both the inputs and outputs of the regression model will be vectors of continuous values. We will see how linear regression models can be easily generalized to work in this case as well, but for the moment we will consider the form above as the general form of a regression model.
28.5.1. Evaluation Measures#
As noted, independently from the employed loss functions, we need evaluation measures to assess the performance of the trained models. Common evaluation measures for regression problems are discussed in the following.
28.5.1.1. Mean Squared Error (MSE)#
Consider a ground truth label \(\mathbf{y} \in \mathfrak{R}^{m}\) and a predicted label \(\widehat{\mathbf{y}} \in \mathfrak{R}^{m}\). Since both values are m-dimensional vectors, a natural way to measure if \(\widehat{\mathbf{y}}\) is a good approximation of \(\mathbf{y}\) is to simply measure their Euclidean distance:
In practice, we often use the squared Euclidean distance to penalize more large errors:
We can compute the average error over the whole test set to obtain a performance estimator, which is usually called Mean Squared Error (MSE):
Where \(TE\) denotes the TEst set.
This performance measure is an error measure. A good regressor will obtain a small error.
Note that the MSE on the test set is equal to the RSS divided by the number of test data points \(|TE|\).
28.5.1.2. Root Mean Squared Error (RMSE)#
The unit of measure of the MSE is the squared unit of measure of the dependent variable (target value). In practice, if \(y\) is measured in meters, then the MSE is measures in square meters. This is not very intuitive. To obtain an error which can be measured in meters, we can take the squared root of the MSE and obtain the Root Mean Square Error (RMSE):
28.5.1.3. Mean Absolute Error (MAE)#
If the target values are scalars (hence \(m = 1\)), another possible measure which has the same unit of measurement as the target variable is the MAE, which is simply the average of the absolute errors:
The main difference between the RMSE/MSE and MAE, is that RMSE/MSE tend to give less importance to small errors, while giving more importance to large errors. This comes from the observation that the squared of a number smaller than one is even smaller than the original number, whereas the squared of a large number is even larger. On the contrary, MAE is often more intuitive (it is the average error we make when estimating y).
28.5.2. Linear Regression as a Predictive Model learned with Empirical Risk Minimization#
We can see linear regression as a form of predictive modeling. Note that, when looking at the linear regressor as a predictive model, we are more interested in its accuracy than in its interpretability. In this context:
We will assume \(\mathcal{X}= \Re^n\), \(\mathcal{Y}= \Re\)
The hypothesis function will take the form:
We will call our dataset the training set;
We will define our loss function as the error function: \(L(h(x),y) = (h(x)-y)^2\);
In this case the empirical risk is defined as follows:
Note that, since:
we can solve the optimization problem with Ordinary Least Squares (OLS) (the same method we used previously to minimize RSS).
From a learning perspective, solving the optimization problem \(\hat h = \underset{h \in \mathcal{H}}{\mathrm{arg\ min}}\ R_{emp}(h)\) corresponds to finding the optimal set of parameters \(\mathbf{\beta}\) minimizing the empirical risk, which corresponds to minimizing the Residual Sum of Squares, as previously defined.
It is worth to emphasize that we are now interested in minimizing the empirical risk as much as possible, even if the model loses interpretability. Hence, we can normalize the data, use many variables, include interaction terms, use polynomial regression, regularize with lasso and ridge, as long as it improves the performance of the model.
28.5.3. Multivariate Linear Regression#
We will now show how the same training algorithm can be used in the case of multivariate linear regression, in which we want map vectors to vectors:
Multivariate linear regression solves the problem by defining \(m\) independent multiple regressors \(h_{i}(\mathbf{x})\) which process the same input \(\mathbf{x}\), but are allowed to have different weights:
Each regressor \(h_{i}\) has its own parameters and their optimizations are carried out independently.
28.5.4. Non-linear Regression#
The consideration made above are valid also in the case of other regression algorithms which allow to go beyond the assumption of linearity. Common examples of non-linear regression models are models with interaction terms, quadratic models, and polynomial models. Other approaches to nonlinear regression such as neural networks exist, but they will not be covered in this course.