15. Density Estimation#
We have seen that clustering algorithms aim to mine the underlying structure of data by breaking it into coherent groups. For example k-means clustering allows to identify parts of the feature space with high density (i.e., a large number of observations) by partitioning all observations into a a discrete sets of \(K\) data groups distributed around centroids.
An alternative smoother approach would be to study the probability \(P(X)\), where \(X\) is the data. Indeed, if we could determine the probability value of an given point in space \(\mathbf{x}\), we could naturally discover clusters in the data (zones with high probability values). Knowing the distribution of the data is also useful for a number of things:
Similar to clustering, if \(X\) is a series of observations of customers in a bank (e.g., age, sex, balance, salary, etc.), we may want to know \(P(X)\) to understand which types of customers are more frequent (those that have large \(P(X)\) values), or if there are different distinct groups of customers (e.g., if \(P(X)\) has more than one mode);
If \(X\) is a set of images of faces, knowing \(P(X)\) would allow us to understand if an image \(x\) looks like an image of a face or not, which faces are more frequent, if there are more than one “groups” of faces, etc. If we could draw \(x \sim P\), we could even generate new images of faces! (by the way, this is what Generative Adversarial Networks do);
If \(X\) is a series of observations of bank transactions, by modeling \(P(X)\) we can infer if a given observation \(\mathbf{x}\) is a typical transaction (high \(P(\mathbf{x}\))) or whether it is an anomaly (low \(P(X)\)). If we can make assumptions on the nature of \(P(X)\),, we can even make inference on the properties of a given data point \(\mathbf{x}\). For instance, if \(P\) is Gaussian, then datapoints which are further from the center are atypical and they can hence identify anomalous transactions.
A probability density is a continuous function, so estimating it is not as straightforward as estimating a probability mass function. There are two main classes of methods for density estimation:
Non-parametric methods: these methods aim to estimate the density directly from the data, without strong assumptions on the source distribution. The main advantage of these methods is that they generally have few hyper-parameters to tune and can be used when no assumption can be made on the source of the data. A disadvantage is that, while we can numerically compute \(f(\mathbf{x})\) with these methods (where \(f\) is the density function), we do not know the analytical form or property of \(f\);
Parametric methods: these methods aim to fit a known distribution to the data. An example of this approach is fitting a Gaussian to the data. The main advantage of these methods is that they provide an analytical form for the density \(f\), which can be useful in a number of contexts (for instance, the density may be part of a cost function we want to optimize). The downside is that these methods make strong assumptions on the nature of the data.
In the following, we will see the main representatives of these two classes of methods.
15.1. Non-parametric Density Estimation Techniques#
We hence usually resort to different approaches, the main of which are:
Fixed windows: this consists in “discretizing” the range of the the variable \(\mathbf{X}\) in “bins” of size \(r\) and counting how many values fall within each window. Histogram belong to this class of methods for density estimation. Note that histograms can also be extended to multiple dimensions by considering d-dimensional tiles (e.g., square tiles in \(\Re^2\));
Mobile windows: as in histograms, the range of \(\mathbf{X}\) the density estimation is performed by dividing the space into d-dimensional windows. However, in this case, the windows are not fixed, but mobile and overlapping, meaning that, given a point \(\mathbf{x}\), we can estimate the density at \(\mathbf{x}\) by centering a window around \(\mathbf{x}\). Kernel density estimation methods as the one we saw at the beginning of the course fall in this category. This is also known as Parzen window.
Fixed samples: rather than discretizing the range of \(\mathbf{X}\), at any given point \(\mathbf{x}\), we estimate the density \(f(\mathbf{x})\) by looking at the \(K\) closest point in space, where \(K\) is fixed and comparing them to the size of a neighborhood containing all of them. We will see that this strategy is used to define the K-NN classification algorithm.
The figure below illustrates three examples of density estimation using the three approaches above for an example dataset.
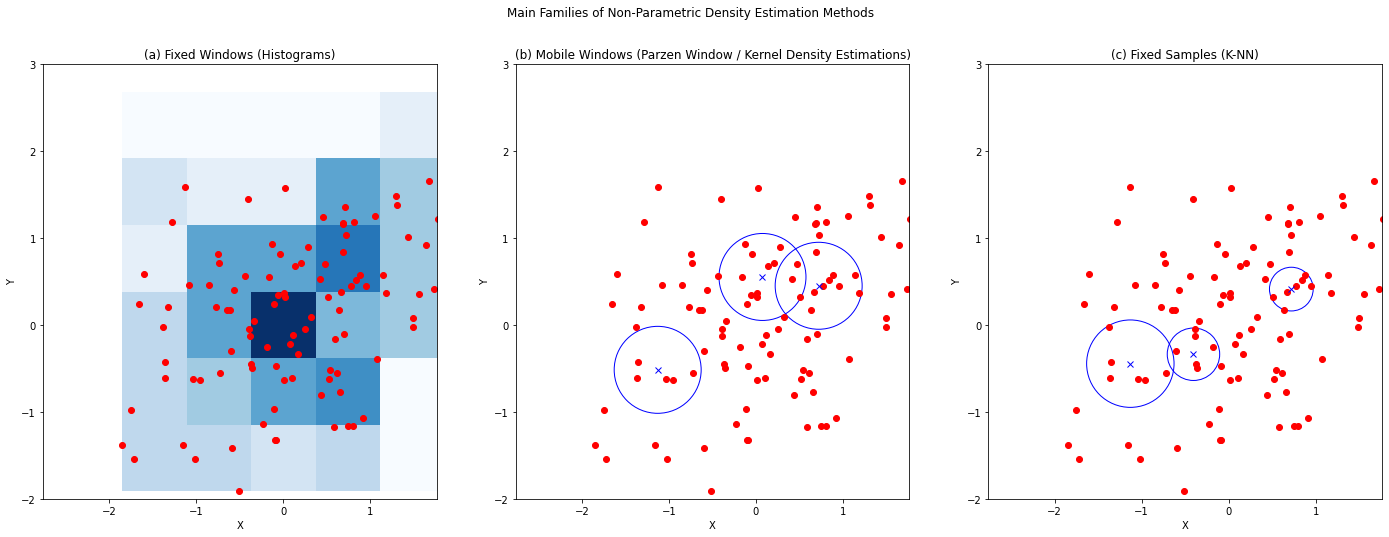
(a) The space is divided into non-overlapping square tiles (other shapes could be used as long as they’ll cover the whole space), then the density for each square is computed by considering the number of examples falling into each square. (b) Given an arbitrary point \(\mathbf{x}\) in the n-dimensional space, a neighborhood of a given radius \(r\) is considered and the density for that point is estimated by considering the number of examples falling in the neighborhood. (c) Given an arbitrary point \(\mathbf{x}\) in the n-dimensional space, we consider a neighborhood centered at \(\mathbf{x}\) and radius \(R_k(\mathbf{x})\) large enough to contain \(K\) points. The density at \(\mathbf{x}\) is computed by considering the size \(R_k(\mathbf{x})\) (the smaller, the denser).
15.1.1. Fixed Windows - D-Dimensional Histograms#
Density estimation can be easily performed using D-Dimensional histograms. This method is the same as the one we saw in the case of 1-d histograms, but in general, we will divide the D-Dimensional space into D-Dimensional regions (typically hypercubes). In the 2D case, these will simply be square tiles. The algorithm hence assigns a uniform density value to each region.
Let \(\mathbf{X}\) be our set of observations and let \(R_i\) be the \(i^{th}\) region of a set of \(\mathcal{R}=\{R_i\}_i\) regions in which we divided the space. We will assign the following density value to the \(R_i\) region:
where \(V(R_i)\) is the volume of \(R_i\). If \(R_i\) is 1-dimensional (hence a segment), this will be its length, if \(R_i\) is 2D, then it will be its area.
Recall that the probability of finding a value \(\mathbf{x}\) in a given region \(R\) is in general given by:
The last part of the equality is true because we assigned uniform density values to each region.
We hence obtain that:
Hence we can treat the density estimate as a valid probability density function.
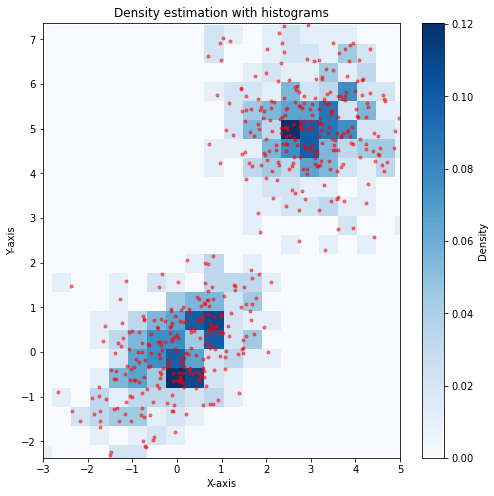
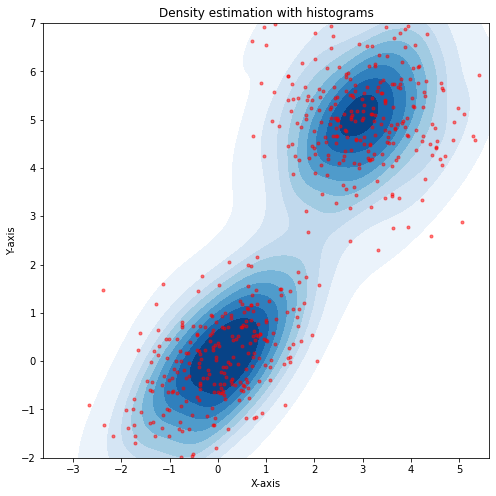
The plot below shows an example density estimation for a set of data. Note that this approach has a few hyper-parameters which determine the size and position of the regions.
Very closely related to the use of histograms for density estimation is the hexplot, a popular visualization techniques in which bins have an hexagonal shape to better approximate more symmetrical circular neighborhoods. The following plot shows an example of hexplot:
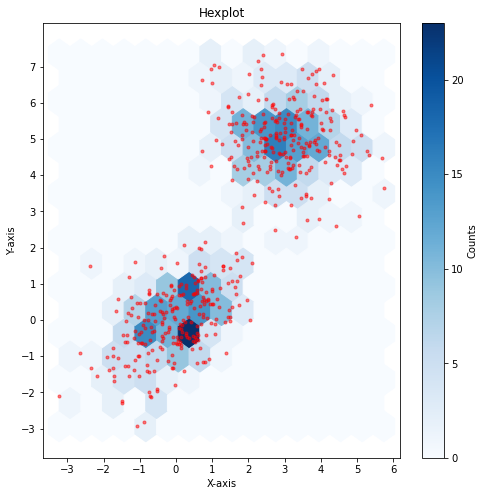
Note that hexplots are not density plots.
15.1.2. Mobile Windows - Parzen Window / Kernel Density Estimation#
While histograms allow to estimate density by placing a fixed grid on the data, the Parzen window approach, also known as kernel density estimation, places a window, or region, around each arbitrary point in space \(\mathbf{x}\). This has the big advantage to allow us to estimate density values at arbitrary points rather than setting fixed density over all points in a region.
A naive approach to density estimation through Parzen Window would assign a point \(\mathbf{x}\) a density by simply computing the fraction of points of \(\mathbf{X}\) which fall between a neighborhood of size \(r\) (where \(r\) is a hyper-parameter) of \(\mathbf{x}\), as follows:
where
is a neighborhood of \(\mathbf{X}\) centered at \(\mathbf{x}\) and of radius \(h\), and \(\alpha\) is a constant introduced to make sure that the density integrates to \(1\):
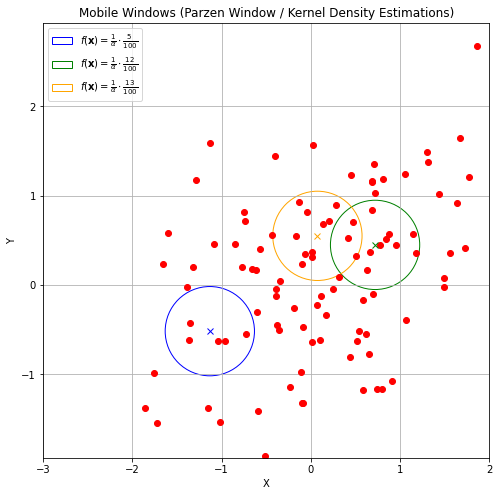
The plot below shows some density estimates using this method:
We can also write the expression above as:
where \(K_h\) is defined as:
We will call \(K_h\) a kernel function depending on the bandwidth parameter \(h\). This is a function which assigns a weight to a point \(\mathbf{x}_i\) depending on its distance from \(\mathbf{x}\). In the example above, we chose \(K_h\) as a circular (or radial) kernel which assigns a uniform score to all points falling in a circle of radius \(h\) centered at \(\mathbf{x}\). The score of \(\frac{1}{\pi h^2}\) is chosen so that the density \(f\) integrates to \(1\).
A main problem with this density estimation approach is that it can be very sensitive on the location at which we are computing the density. Indeed, we can find cases in which we obtain very different density when we move the circle by a little bit.
We can note that this is due by the kernel \(K\) making “hard decisions” on which elements to assign a non-zero score and which ones to assign a zero score. Indeed, if we plot the kernel as a function of the distance between \(\mathbf{x}\) and \(\mathbf{x}_i\), rescaled by \(h\), we obtain the following picture:
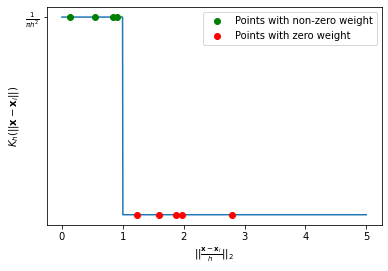
The plot also plots points putting their distance from \(\mathbf{x}\) in the x axis and the assigned weight in the y axis. As can be noted, even very close points in the x axis (e.g., the last of the green ones and the first of the red ones) get assigned very different weights, which makes the overall process sensitive to small shifts.
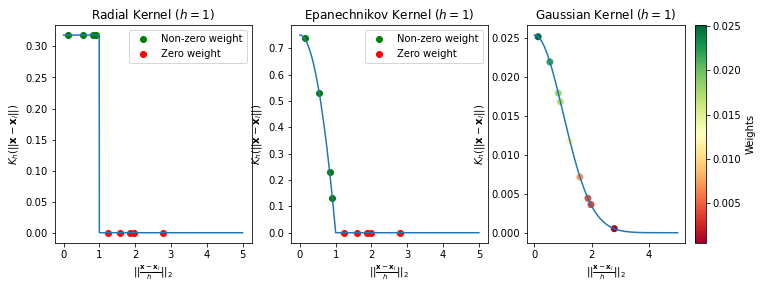
To reduce this effect, it is common to use a smoother kernel which assigns a decreasing weight to points as their distance from \(\mathbf{x}\) grows. Common choices for kernels are the Epanechnikov kernel and the Gaussian Kernel, which are defined as follows:
Epanechnikov Kernel
where \(\mathbb{I}\) is the indicator function defined as:
Gaussian Kernel
where \(d\) is the dimensionality of the data (\(2\) in our examples).
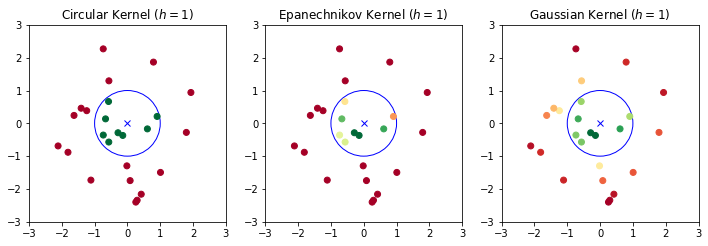
The plot below compares the scores assigned to points depending on their distance from \(\mathbf{x}\) according to the three kernels seen so far:
This can be seen in 2D as follows:
The following plot shows an example of Kernel Density estimation on a sample dataset:
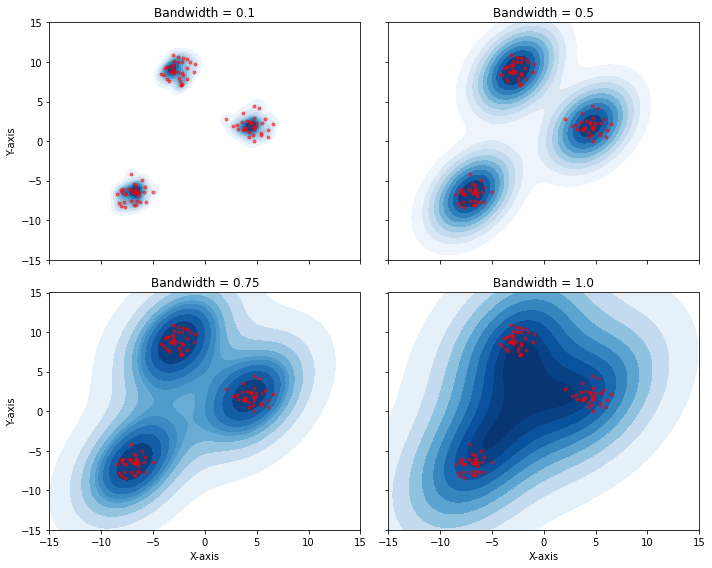
Note that the bandwidth changes the sensitivity of the algorithm. Low bandwidth values (small circles), will make the estimation more sensitive to shifts. Large bandwidth values (large circles) will make the estimation more stable, but the final density may not capture all details of the distribution.
Also in this case, the bandwidth regulates the trade-off between variance and bias.
The plot below shows density estimations for different bandwidth values:
15.1.3. Fixed Samples - K-Nearest Neighbor#
With either histograms or mobile windows, we have considered regions with a fixed size (e.g., the bandwidth \(h\)). In practice, this will lead to regions with very few or zero examples and regions with many examples. This can lead to some limitations as density estimates relying on fewer points will be more unstable (they will have a higher variance) and we will not be able to reliably estimate a density in areas where there are fewer points.
While one way to mitigate this is to use smoother kernels (e.g., the Gaussian one) assigning a non-zero weight to each example, another approach is to choose a neighborhood of \(\mathbf{x}\) such that the number of elements in the neighborhood, besides \(\mathbf{x}\) is exactly equal to \(K\), where \(K\) is an hyper-parameter. The advantage of this approach is to always rely on the same sample sample size when estimating the density.
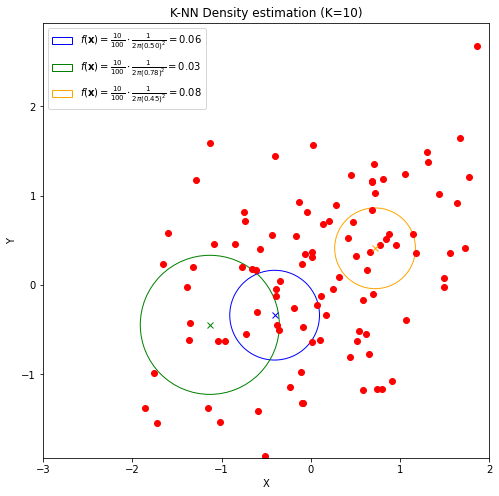
Let \(N(\mathbf{x},r)\) be a neighborhood centered at \(\mathbf{x}\) with radius \(r\). We will define \(R_K\) as the radius of the largest neighborhood centered at \(\mathbf{x}\) containing at most \(K\) examples, besides \(\mathbf{x}\) (if it is included in \(\mathbf{X}\)):
We will also define \(N_K(\mathbf{x})\) as the largest neighborhood of \(\mathbf{x}\) containing at most \(K\) elements:
K-NN density estimation will assign point \(\mathbf{x}\) the following density estimate:
Where \(V_d\) is the volume of the unit d-dimensional ball and \(V_d \cdot R_k^d(\mathbf{x})\) is hence the volume of the d-dimensional ball of radius \(R_K(\mathbf{x})\). Intuitively, if \(R_k(\mathbf{x})\) is large, then we are in an area which is not very dense, so we will assign a small density value.
The figure below exemplifies the computation in 2D:
The plot below shows density estimates for different values of \(K\):
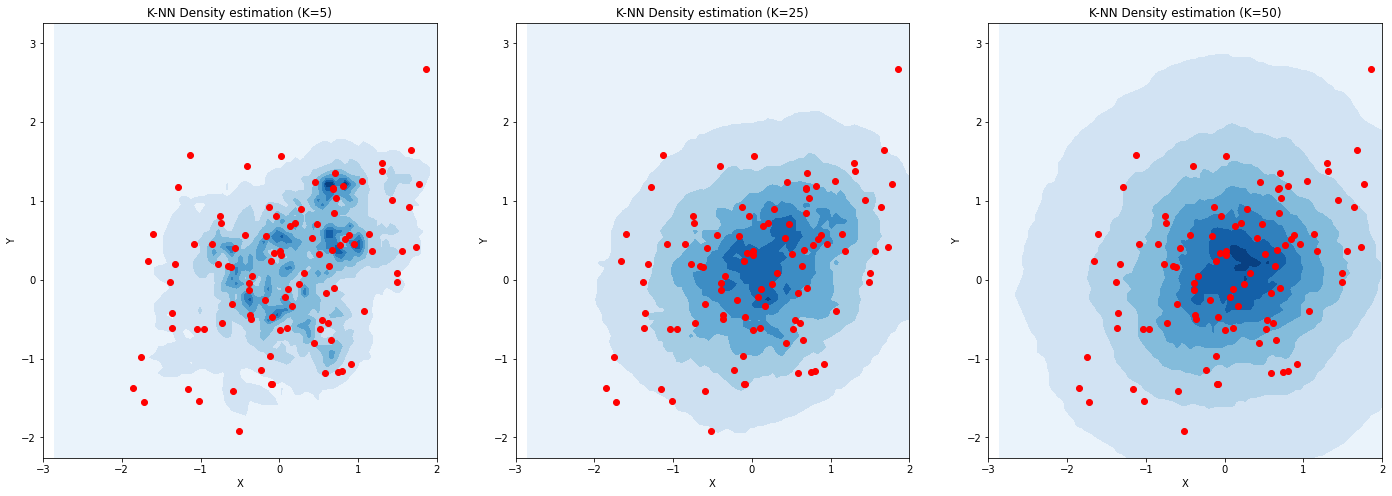
As we can see, \(K\) acts as the bandwidth in the previous case, effectively determining the size of the neighborhoods in an adaptive way.
We will not see more details on this method, as kernel Density Estimation is in practice the most used non-parametric density estimation method. However, we will see how this approach will turn useful and practical to define classification algorithms.
15.2. Parametric Density Estimation#
Parametric methods aim to estimate density by fitting a parametric model to the data. This has some advantages over non-parametric density estimation:
The chosen model has in general a known analytical formulation which we can reason on, or that we can even plug into a cost function and differentiate to pursue some optimization objective;
The chosen model is compact. While non-parametric models need to keep in memory the whole dataset to make density estimations at given points, once fitted, parametric models can be used to predict density values using the analytical formulation of the model;
If we choose an interpretable model, we can reason on the model to derive properties of the data. For instance, if we fit a Gaussian on the data, then we know that the mean is the point with highest density. We also know that when we go further from the mean, the density values decrease.
Nevertheless, these methods also have disadvantages:
An optimization process is required to fit the model to the data, i.e., find appropriate values which make the model “explain well the data”. This can be a time-consuming process.
Parametric models make strong assumption on the data. For instance, if we fit a Gaussian to the data, we assume that the data is distributed in a Gaussian way. If this is not true, then the model will not be very accurate. This is a relevant point, as in many cases we cannot make strong assumptions on the data.
For the reasons above, it is common to use non-parametric density estimations for visualizations (e.g., the density plots we have seen and used in many cases), especially for exploration, when we do not know much about the data, and to use parametric model when we need to create efficient models able to make predictions (as we will see later in the course).
15.2.1. Fitting a Gaussian to the Data#
Recall the PDF of a multivariate Gaussian distribution with \(n\) dimensions:
Let \(\mathbf{X} = \{\mathbf{x}_1, \ldots, \mathbf{x}_N\}\) be a set of observations which we will assume to be independent and drawn from a multivariate Gaussian distribution of unknown parameters. We would like to find the parameters \(\mathbf{\mu}\) and \(\mathbf{\Sigma}\) that identify the most likely Gaussian distribution that may have generated the data. To do so, we can use the Maximum Likelihood (ML) principle, which consists in finding the parameters which maximize the probability values that the Gaussian distribution would compute for the given data. The likelihood is defined as
Intuitively, we want to find \(\mathbf{\mu}\) and \(\mathbf{\Sigma}\) parameters such that the Gaussian distribution will assign high probability values to the observed points \(\mathbf{x}\), i.e., such that observing our dataset is highly probable under the given model.
Let us consider a simple example in which we want to fit a Gaussian to a set of 1D data. The plot below shows the log likelihood for Gaussians with different means and standard deviations.
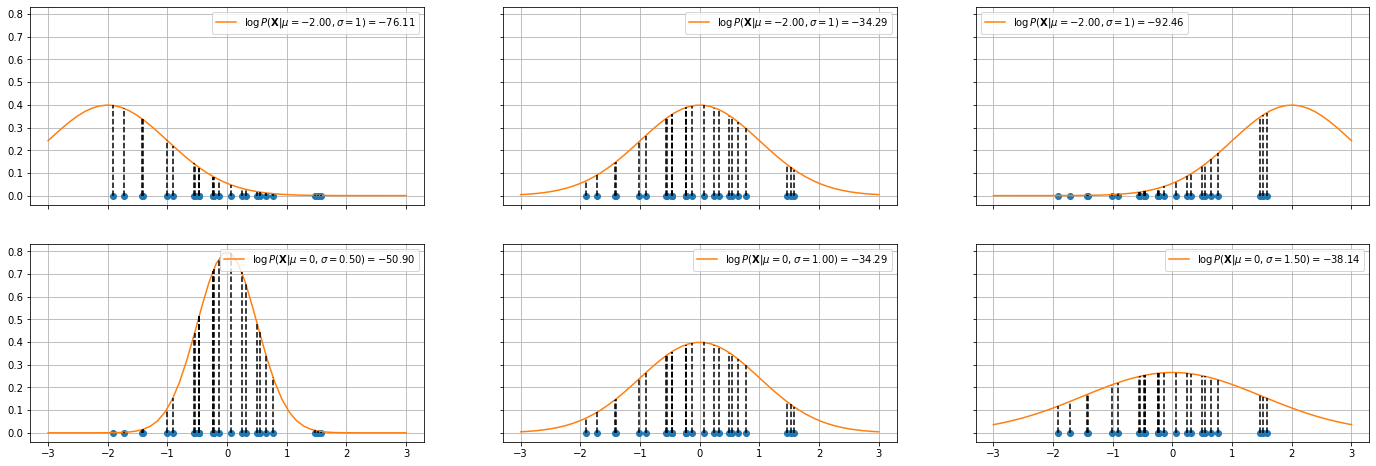
In the top plots, the standard deviation is fixed to \(1\), while the mean of the Gaussian is changed. The log likelihood is shown in the legend. As can be seen, the mean in the center plot leads to larger log likelihood. Intuitively, this happens when we choose a mean such that the majority of points fall in the central part of the Gaussian distribution.
The plots in the bottom show a similar example in which the mean is fixed to \(0\) and the standard deviation is varied. As can be noted, when the standard deviation is too low (left) or to high (right), we obtain smaller log likelihoods.
The plots below show the log likelihood (first two plots) or the likelihood (last plot) as a function of different values of means and standard deviations.
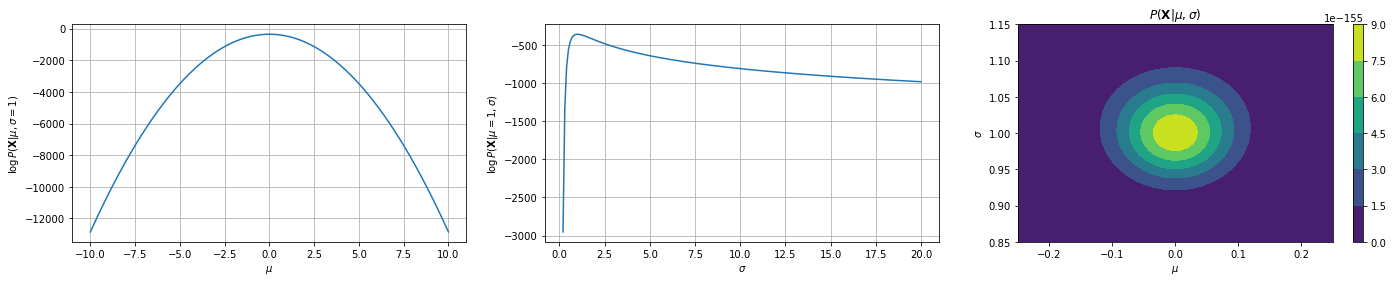
The first two plots show how the log likelihood changes when \(\mu\) and \(\sigma\) change, keeping the data fixed (same data as the previous plot). The last plot shows how the likelihood changes as a function of both \(\mu\) and \(\sigma\). As we can see, we have a maximum for \(\mu=0\) and \(\sigma=1\), which are the true parameters of the distribution which generated the data.
It can be shown that a close form solution exist for the estimation of the parameters of the N-Dimensional Gaussian. These are obtained by computing the derivatives of the log likelihood with respect to \(\mathbf{\mu}\) and \(\mathbf{\Sigma}\) and setting them to zero. We will not see the mathematical details, but the Maximum Likelihood estimates of the parameters for the n-dimensional Gaussian are:
and
We are very familiar with the first expression - it is simply the mean of the data. The second expression is the data covariance matrix.
To see why the expression above denotes the covariance matrix, let us consider a set of 2D points \(\mathbf{x}_i=(x_{i1},x_{i2})\) and the mean value \(\mathbf{\mu}_{ML} = (\overline{x}_1,\overline{x}_2)\). We have:
Which is the definition we have seen in the past for the covariance matrix.
15.2.2. Gaussian Mixture Models (GMM)#
We have seen that, when we can assume that the data follows a Gaussian distribution, it can be convenient to fit a D-dimensional Gaussian to the data and summarize the data with distribution. In practice, this consists in estimating a D-dimensional mean vector \(\mathbf{\mu}\) and a \(D \times D\) covariance matrix \(\mathbf{\Sigma}\).
In practice, however data is not always Gaussian. As we have seen in the case of clustering, we can expect that our data is actually grouped under different clusters. Think about the Old Faithful dataset. Since the data has two modes, a Guassian model would lead to a poor fit.
The plot below compares a Guassian fit with a Kernel Density Estimation form the same data. The data has been standardized.
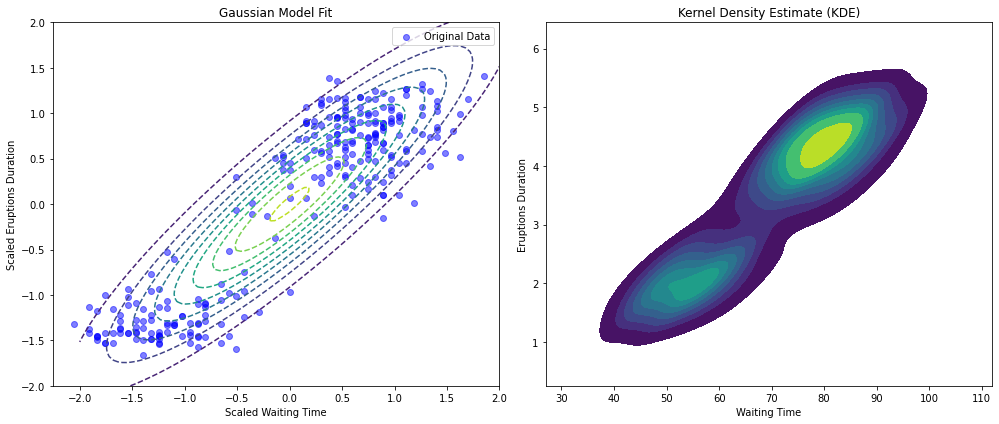
As can be seen, the unimodal Guassian distribution is not a good fit. Indeed, the center of the Gaussian lies in an area with low density, as shown by the density estimation on the right.
An alternative approach would consist in fitting two separate Gaussian distributions to the two clusters of data, as shown in the following:
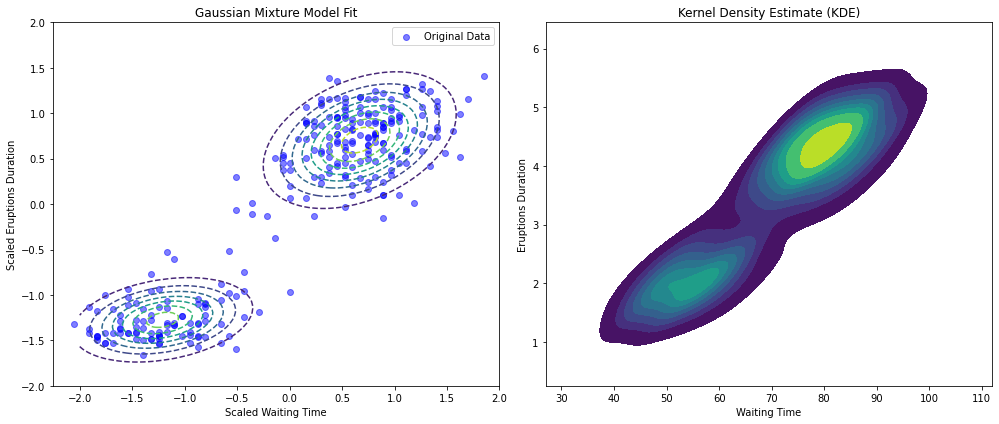
We could then define a unified probability distribution averaging the two distributions:
where \(\mathcal{N}(\mathbf{x}|\mathbf{\mu}_k, \mathbf{\Sigma}_k)\) is the normal distribution of mean \(\mathbf{\mu}_k\) and covariance matrix \(\mathbf{\Sigma}_k\) computed at point \(\mathbf{x}\).
More in general, we may want to weigh more one distribution over the others. We can hence define the following general model:
This model is known as a Gaussian Mixture Model (GMM). Each Gaussian \(\mathcal{N}(\mathbf{x}|\mathbf{\mu}_k, \mathbf{\Sigma}_k)\) is called a component of the GMM. The parameters \(\pi_k\) are called mixing coefficients and are defined such that:
and
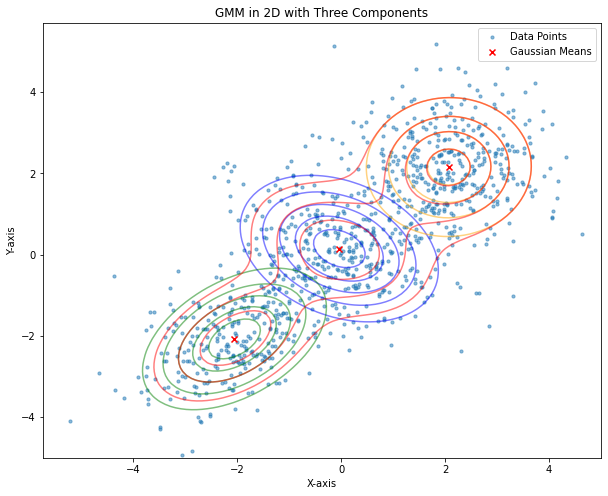
The following plot illustrates an example of a 1D Gaussian Mixture Model with three components:
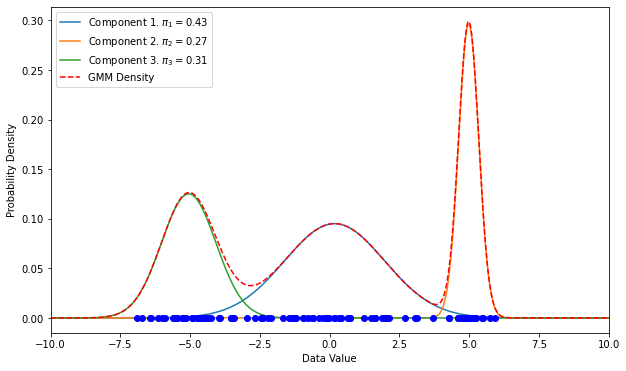
A similar plot in 2D is shown below:
15.2.2.1. Optimization by Maximum Likelihood#
The Gaussian Mixture Model depends on the following parameters:
Similarly to what seen for Gaussian models, we can optimize Gaussian Mixture Models with Maximum Likelihood. Assuming that the observations \(\mathbf{x}_i \in \mathbf{X}\) are independent and identically distributed, we can define the likelihood of the data, given the model as follows:
Rather than maximizing the likelihood above, we can maximize the logarithm of the likelihood:
This optimization process is not straightforward and there is no closed form solution. Instead, it can be optimized through iterative numerical methods or with a powerful algorithm called Expectation-Maximization. Before delving into that, it is useful to see the GMM from a probabilistic perspective.
15.2.3. Probabilistic Formulation of GMM with Latent Variables#
We will now give a probabilistic treatment of the GMM. This will lead us to the interpretation of the model as one with latent variables and to the illustration of the Expectation-Maximization (E-M) algorithm for maximum likelihood optimization.
We will start by introducing a \(K-dimensional\) random variable \(\mathbf{Z}\). The values \(\mathbf{z}=(z_1,\ldots,z_K)\) assumed by \(\mathbf{Z}\) will be such that:
In practice, \(\mathbf{Z}\) has a one-hot representation, with only one of its components \(z_k\) being equal to \(1\) at a given time and the others being equal to \(0\).
We can also see \(Z\) as a categorical variable assuming values going from \(1\) to \(K\), with value \(k\) being represented by the vector \(\mathbf{z} = (z_1=0, z_2=0, \ldots, z_k=1, \ldots, z_K=0)\). If we denote such vector as
then we can also write \(\mathbf{Z} = H_k^K\) to denote that variable \(\mathbf{Z}\) assumes value \(k\).
We will assume that \(\mathbf{Z}=H_k^K\) encodes the event \(\mathbf{X}\) belongs to component \(k\) of the GMM. This means that any example \(\mathbf{x}_i\) will be associated to a related value \(\mathbf{z}_i\) of the introduced variable \(\mathbf{Z}\), which will effectively assign \(\mathbf{x}_i\) to one of the \(K\) components of the GMM.
Latent Variables
We will call the newly introduced variable \(\mathbf{Z}\) a latent variable. Indeed, while \(\mathbf{Z}\) has a clear semantic, this stems from an assumption made at the model-level. Hence, we cannot directly observe the values of \(\mathbf{Z}\) as we can instead do for \(\mathbf{X}\), which will be called an observed variables (most of the variables we have seen so far in the course are observed variables). Nevertheless, being able to determine the values of \(\mathbf{Z}\) has a very practical implication, as these values can be used, for instance, to cluster the data, or to find the best parameters of each of the components.
We’ll assume that \(\mathbf{Z}\) follows a categorical distribution with probability vector \(\mathbf{\pi}=(\pi_1, \pi_2, \ldots, \pi_K)\), hence:
with:
Note that since \(\mathbf{z}\) is encoded as a one-hot vector, we can write more compactly:
Once we fix a value \(z_k=1\) for the latent variable \(\mathbf{Z}\), we will express the probability of \(\mathbf{x}\), conditioned on \(z_k=1\) with a Gaussian of appropriate parameters \(\mathbf{\mu}_k\) and \(\mathbf{\Sigma}_k\):
Following the notation above, we can also write:
Note that, since we want to estimate the density of \(\mathbf{X}\), we wish to find values for \(P(\mathbf{x})\). Applying the product rule and the sum rule, we obtain the following marginal probability:
This leads us to the same exact definition of the GMM seen previously, but within a probabilistic framework where we also have access to the joint distribution \(p(\mathbf{x,z})\), which will be useful when we’ll introduce the Expectation Maximization algorithm to maximize the likelihood and hence optimize the model.
15.2.3.1. Inferring Values for the Latent Variable \(\mathbf{Z}\)#
Another interesting interpretation is that, to each observed \(\mathbf{x}_i\) value, we will implicitly assign a corresponding \(\mathbf{z}_i\) value indicating to which component of the Gaussian Mixture Model the observation belongs. This is useful, as it will allow us to use the GMM model as a clustering algorithm in which we can determine to which cluster each data point belongs.
In practice, this can be done by finding the \(z_k\) value for which the following quantity is maximized:
Since there are only \(K\) possible \(z_k\), maximizing the expression above is trivial: we just compute it for all values of \(k\) and select the \(k\) value which maximizes the conditional probability above:
Using Bayes’ theorem, we obtain:
where we noted that:
In Bayesian terms, we can see \(\pi_k\) as the prior probability that \(\mathbf{x}\) belongs to component \(k\), while \(\gamma(z_k)\) is the posterior probability, after we have observed \(\mathbf{x}\). The term \(\gamma(z_k)\) is also called the responsibility that component \(k\) takes for “explaining” the observation \(\mathbf{x}\).
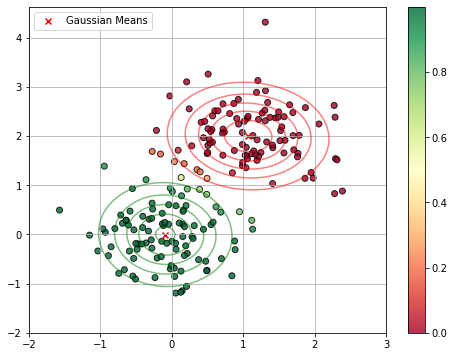
Given this interpretation, we can see a GMM as a probabilistic version of K-Means clustering, in which each example is associated to a probability of belonging to a given cluster (or component). The plot below illustrates this by showing a GMM with 2 components fitted to a 2D dataset. Data points are colored according the predicted probability of belonging to first component.
As can be noted, points in between the two clusters are assigned “uncertain” probability values.
15.2.3.2. Sampling from a GMM#
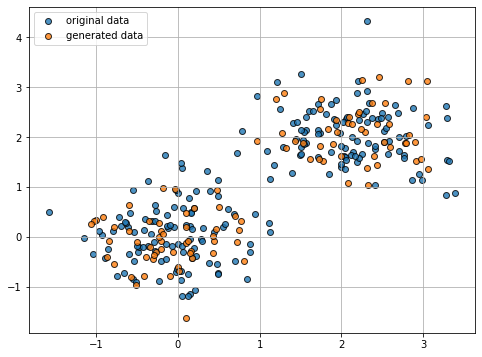
Note that this formulation of the GMM allows us to generate data new points \(\hat{\mathbf{x}}\) which would follow the distribution of the original data. This is done by following a techniques such as the following one, which is also known as ancestral sampling:
We first sample a variable \(\hat{\mathbf{z}}\) from the marginal distribution \(P(\mathbf{z})\). Note that this distribution is a categorical one;
We then sample \(\mathbf{x}\) from the conditional probability \(P(\mathbf{x}|\hat{\mathbf{z}})\). Note that, once \(\hat{\mathbf{z}}\) is fixed, the conditional distribution will simply be a Gaussian distribution with a given mean \(\mathbf{\mu}_k\) and covariance matrix \(\mathbf{\Sigma}_k\).
Standard methods exist for sampling from categorical and Gaussian distributions, but we will not see them in details.
The plot below shows a set of data together with another set of data generated from a GMM fit to the original data. As can be seen, the data follows a similar distribution.
15.2.4. The Expectation-Maximization Algorithm for GMM#
As discussed earlier, we wish to maximize the logarithm of the likelihood, which we have seen assumes the following form:
We will not see all mathematical steps, but if we compute the derivative of the expression above with respect to the means \(\mathbf{\mu}_k\) of the Gaussian components and set it to zero, we obtain that optimal means can be obtained by the following expressions:
where \(z_{ik}\) is the k-th component of the \(\mathbf{z}_i\) value associated to the observation \(\mathbf{x}_i\) and
Recall that \(\gamma(z_{ik}) = P(\mathbf{z}_i = H_k^K|\mathbf{x}_i)\), hence we can see \(N_k\) as a “soft count” of the number of elements belonging to each component (or alternatively, in each cluster). The count is “soft” because the \(\gamma(z_{ik})\) are probability values. If \(\gamma(z_{ik})\) were extreme probabilities (either \(0\) or \(1\)), \(N_k\) would be the actual of elements in each cluster.
We can see the expression above for the estimation of the optimal mean for the k-th component \(\mathbf{\mu}_k\) as the average of all data points \(\mathbf{x}_i\), weighted by the probabilities \(\gamma(z_{ik})\) that each of these data points belong to the k-th components, rescaled by the soft count of the number of elements assigned to the k-th components. Note that if probabilities \(\gamma(z_{ik})\) were again binary (either \(0\) or \(1\)), the estimation above would become identical to the update step of K-Means, so in some sense, we can see it as a “soft”, probabilistic version of it.
If we set the derivative of \(\log P(\mathbf{x}|\mathbf{\pi}, \mathbf{\mu}, \mathbf{\Sigma})\) with respect to \(\mathbf{\Sigma}_k\) to zero, we obtain the following expression for the optimal covariance matrix:
Recall that the ML estimation of the covariance matrix for fitting a D-dimensional Gaussian to the data is:
The two expressions are similar, but in the case of GMMs, we are weighing each data point \(\mathbf{x}_i\) by the responsibility \(\gamma(z_{ik})\) and the denominator is given by the “soft count” of points assigned to component \(k\).
We finally set to zero the derivative of the log likelihood with respect to the mixing coefficients \(\pi_k\) and obtain the following expression for the estimation of the optimal values:
Hence, the mixing coefficient for component \(k\) is given by the soft count \(N_k\) of points assigned to component \(k\) divided by the total number of points \(N\).
We shall note that results (A), (B) and (C) do not constitute a closed form solution to find the parameters of the mixture model. Indeed, they depend on the responsibilities \(\gamma(z_{ik})\) in a complex way. Moreover, we have a chicken and egg problem. Indeed:
To estimate (A), (B) and (C) we need to be able to compute the responsibilities \(\gamma(z_{ik})\), but to compute these values, we first need to have estimates for \(\mathbf{\mu}_k\) (A), \(\mathbf{\Sigma}_k\) (B), and \(\pi_k\) (C).
While we do not have a closed form solution for the estimation of the parameters, we can apply a simple iterative scheme, which is an instance of the Expectation Maximization (EM) algorithm applied to the specific case of the Gaussian mixture model.
The iterative scheme works as follows:
We choose some initial values for \(\mathbf{\mu}_k\), \(\mathbf{\Sigma}_k\) and \(\pi_k\). A common initialization scheme consists in running a K-Means clustering and then fitting K Gaussian distributions, one for each cluster. We compute the initial value of the log likelihood.
We alternate through two steps:
Expectation (or E step): we use the current estimates of the parameters to find the responsibilities - these are the posterior probabilities of assigning a given data point \(\mathbf{x}_i\) to a given component \(k\), after seeing the data point \(\mathbf{x}_i\) and given the model parameters. It’s called “expectation” step as we will compute the expected assignment of points to components given the data points and the fixed parameters.
Maximization (or M step): we now assume that the assignment given by the responsibilities is correct and use the \(\gamma(z_{ik})\) values to re-estimate the parameters of the model through the equations (A), (B), and (C). We update the value of the log likelihood.
We stop iterating when a given maximum number of iterations has been reached or when the difference between new log likelihood value and the old one is very small (below a given threshold).
It can be shown (but we will not formally see it) that each E step followed by an M step is guaranteed to increase the log likelihood (and hence the likelihood). Hence the algorithm will converge sooner or later.
15.2.4.1. Pseudocode#
The box below summarizes the algorithm in pseudocode:
Initialize the means \(\mathbf{\mu}_k\), covariances \(\mathbf{\Sigma}_k\) and mixing coefficients \(\pi_k\). A possible initialization is to run a K-Means with \(k\) clusters and fit \(K\) Gaussian distributions, each on each cluster. Initial mixing coefficients can be chosen as the fractions of data points assigned to each cluster. Compute an initial value for the log likelihood using the formula:
\[\log P(\mathbf{X}|\mathbf{\pi}, \mathbf{\mu}, \mathbf{\Sigma}) = \sum_{i=1}^N \log\left[\sum_{k=1}^K \pi_k \mathcal{N}(\mathbf{x_i}|\mathbf{\mu}_k, \mathbf{\Sigma}_k)\right]\]Repeat until termination criterion is reached {
E Step: Compute responsibilities using the current parameter values using the formula:
\[\gamma(z_k) = \frac{\pi_k \mathcal{N}(\mathbf{x}|\mathbf{\mu}_k \mathbf{\Sigma}_k)}{\sum_{j=1}^K \pi_j \mathcal{N}(\mathbf{x}|\mathbf{\mu}_j \mathbf{\Sigma}_j)}\]M Step: Estimate the parameter values using the current estimate for the responsibilities using the following formulas:
\[\mathbf{\mu}_k = \frac{1}{N_k} \sum_{i=1}^N \gamma(z_{ik})\mathbf{x}_i \ \ \ \ \ \text{(A)}\]\[\mathbf{\Sigma}_k = \frac{1}{N_k} \sum_{i=1}^N \gamma(z_{ik}) (\mathbf{x}_i - \mathbf{\mu}_k) (\mathbf{x}_i - \mathbf{\mu}_k)^T \ \ \ \ \ \text{(B)}\]\[\pi_k = \frac{N_k}{N} \ \ \ \ \ \text{(C)}\]with
\[N_k = \sum_{i=1}^N \gamma(z_{ik})\]Re-evaluate the log likelihood using the formula:
\[\log P(\mathbf{X}|\mathbf{\pi}, \mathbf{\mu}, \mathbf{\Sigma}) = \sum_{i=1}^N \log\left[\sum_{k=1}^K \pi_k \mathcal{N}(\mathbf{x_i}|\mathbf{\mu}_k, \mathbf{\Sigma}_k)\right]\]}
15.2.4.2. Example Execution#
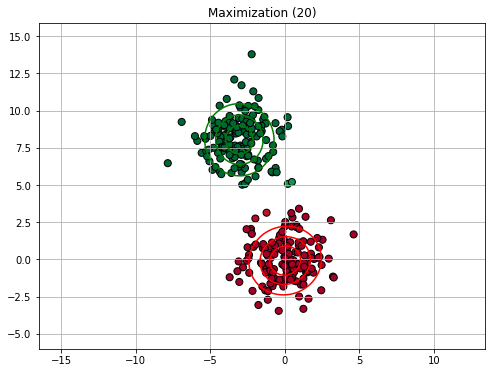
Similarly to K-Means clustering, we will now see an example execution of the E-M algorithm. We will consider a GMM with 2 components. Since the EM algorithm is slower than K-Means, we will not show all iterations.
We will consider the following synthetic dataset:
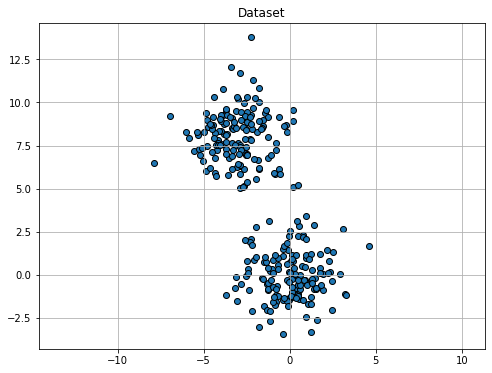
Rather than initializing with K-Means, we consider an ad-hoc initialization (imagine this to be random) to illustrate the process.
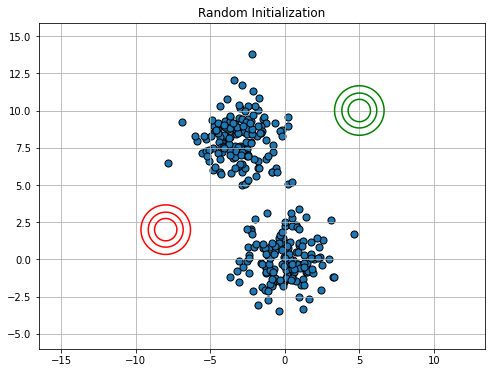
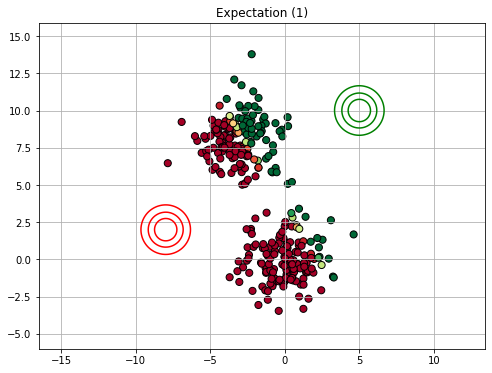
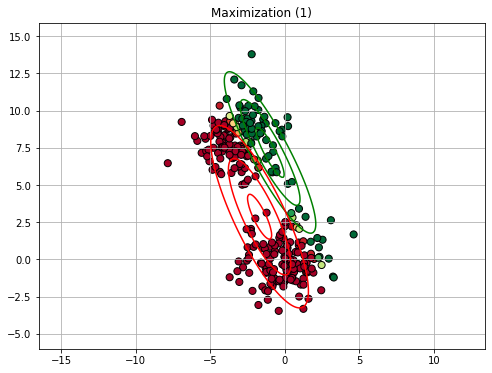
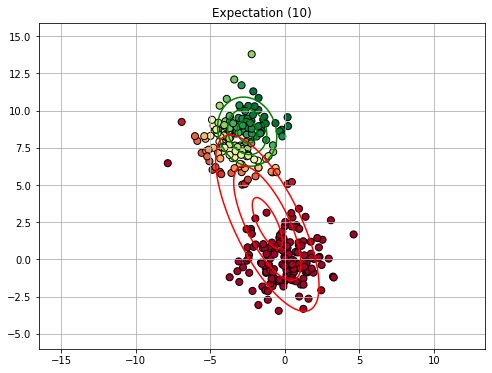
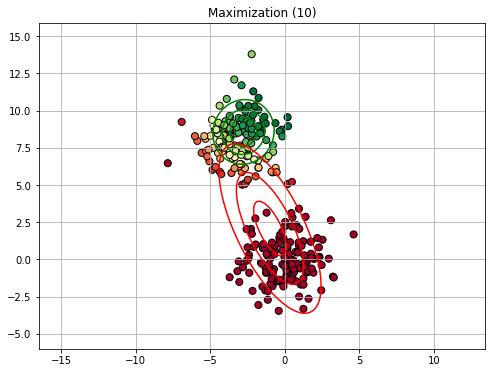
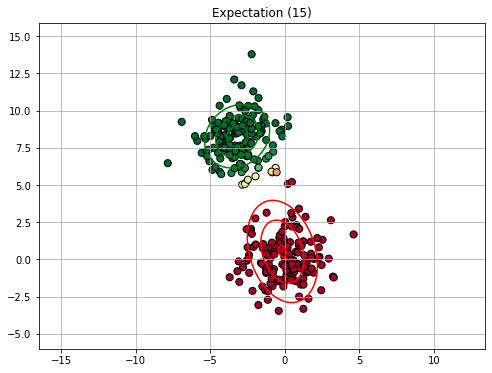
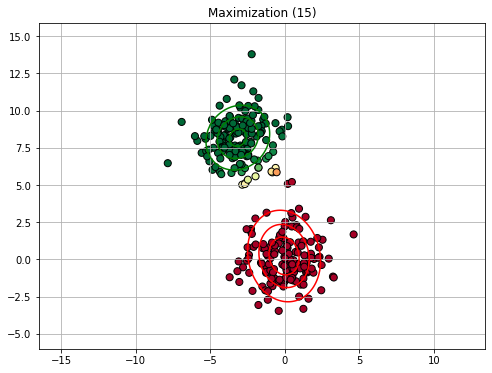
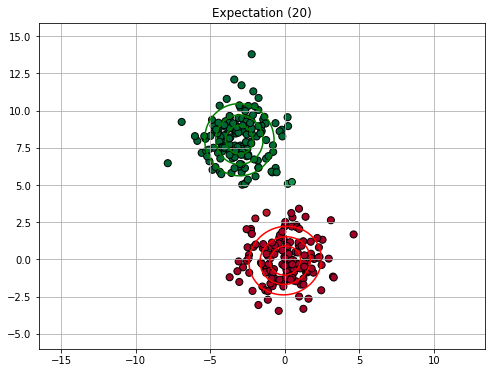
15.2.4.3. Expectation Maximization in General#
We have seen the EM algorithm instantiated to the optimization of GMMs. However, the EM algorithm is a general framework for finding maximum likelihood estimates of parameters in models with latent variables. As such, it can be applied also in other contexts in which the Maximum Likelihood estimates lead to a “chicken and egg” problem, in which we need to be able to estimate the probability of latent variables to fit a model to the observed data, but, at the same time, we need to fit the model to the data to model latent variables.
15.2.5. GMM vs K-Means#
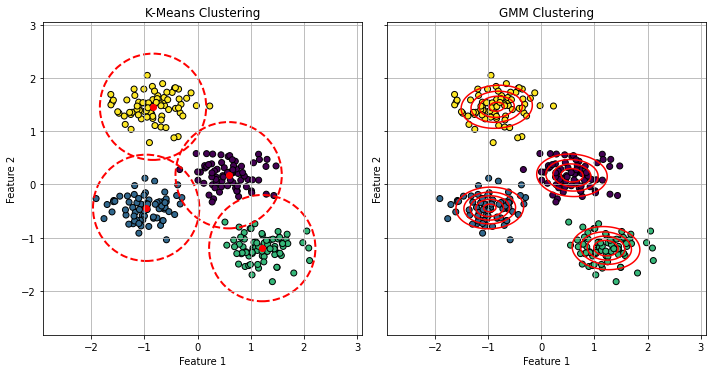
The EM algorithm is very similar to the optimization algorithm of K-Means. It can be shown that K-Means can be seen as a particular case of Gaussian Mixture Models in which:
Points are assigned to clusters in a “hard” way, as compared to the soft assignment made by the responsibilities \(\gamma(z_{ik})\) in Gaussian Mixture Models;
Clusters are assumed to have diagonal covariance matrices \(\epsilon \mathbf{I}\) where \(\mathbf{I}\) is the \(D \times D\) identity matrix and \(\epsilon\) is a variance parameter which is shared by all components. This means that the clusters are assumed to be all symmetrical and with the same shape.
Despite these differences highlight the limitations of K-Means, it should be considered that K-Means is a significantly faster algorithm than GMM. Hence, if studying the probability density \(P(\mathbf{X})\) is not needed and we can assume symmetrical clusters with similar shapes, K-Means is in practice a more popular choice, due to its faster convergence.
The plot below illustrates such differences:
15.3. References#
Section 19 of notes of the course “Fondamenti di Analisi dei Dati” 2022/2023 - Prof. Giovanni Gallo
https://en.wikipedia.org/wiki/Multivariate_kernel_density_estimation
http://faculty.washington.edu/yenchic/18W_425/Lec7_knn_basis.pdf
Section 9.2 of [1]
[1] Bishop, Christopher M., and Nasser M. Nasrabadi. Pattern recognition and machine learning. Vol. 4. No. 4. New York: springer, 2006.